'{a} and {b} and {a}'.format(a='you', b='me')import sys
print('User Current Version : ', sys.version)
print("User Current Version : ", sys.version)
print('User Current Version : ', sys.version_info)
from platform import python_version
print('User Current Version : ', python_version())
'print('User Current Version : ' python_version())'
# 문자열
'문자열'
"문자열"
print('Hello, World!')
print('오늘 하루도 열심히 공부하자!!')
# print separator 옵션 sep=' ' 기본값
# PL/SQL = || 연산자
print('h', 'e', 'l', 'l', 'o')
print('h', 'e', 'l', 'l', 'o', sep=' ')
print('h', 'e', 'l','l', 'o', sep='')
print('h', 'e', 'l','l', 'o', sep=',')
print('2023', '11', '13')
print('2023', '11', '13', sep='-')
print('james', 'itwill.com', sep='@')
# 한줄로 출력하길 희망할 경우, 한꺼번에 블럭잡고 F9. end=' '
# end 옵션을 이용해서 서로 다른 출력을 하나의 출력문자로 출력할 수 있다.
print('환영합니다.', end=' ')
print('itwill에', end=' ')
print('잘 오셨습니다.')
print('{} and {} '.format('you', 'me'))
'{} and {} '.format('you', 'me')
# 위치지정방식
'{0} and {1} and {0}'.format('you', 'me')
# 이름지정방식(변수)
# PL/SQL = =>
'{a} and {b} and {a}'.format(a='you', b='me')
# 사칙연산
1+2
2-1
2*3
7/2
# 몫
7//2
# 나머지
# SQL : SELECT mod(7, 2) FROM dual;
7%2
# 제곱연산
# SQL : SELECT power(2,3) FROM dual;
2**3
# 데이터 타입 확인
type(2**3) # 정수형
# import 하기
import math
math.pow(2, 3)
type(math.pow(2, 3)) # 실수형
# 연산자 우선순위
# PL/SQL 과 동일
1. ** (제곱연산자)
2. *, /, //
3. +, -
(1 + (2 * (3 ** 3)))
■ 변수(variable)
- 데이터를 저장할 수 있는 메모리 공간
- 첫 번째 글자 : 영문, 한글, _(밑줄)
- 두 번째 글자 : 영문, 한글, 숫자, _
- 대소문자 구분
- 예약어는 사용할 수 없다.
import keyword
keyword.kwlist
type(keyword.kwlist) # list(type) : 1차원 배열 []
x = 10
type(x)
X = 100
# 메모리에 생성된 변수, 함수, 클래스, 객체들 확인
dir()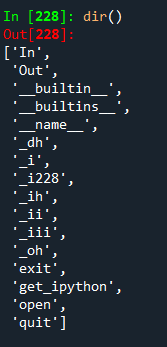
# 변수 삭제
del x
# 연산자 축약
x = 1
x += 1 # x = x + 1
x -= 1
x *= 1
x /= 2
x //= 3
x %= 3
# input 입력 처리는 함수, 문자값으로 받는다.
amount = input('Enter amount to withdraw : ')
amount
type(amount)
amount // 50000
# input 앞에 int() 형변환 -> 문자숫자를 정수형으로 변환하는 함수
amount = int(input('Enter amount to withdraw : '))
type(amount)
# float : 문자숫자를 실수형으로 변환하는 함수
amount = float(input('Enter amount to withdraw : '))
type(amount)
# divmod : 몫과 나머지 값을 리턴하는 함수(몫(//), 나머지(%))
divmod(amount, 50000)
type(divmod(amount, 50000))- 자료형(tuple) type
# 몫과 나머지를 각각의 변수로 지정
fiftythousandwon, r = divmod(amount, 50000)
fiftythousandwon #몫
r #나머지
divmod(r, 10000)
tenthousandwon, r = divmod(r, 10000)
divmod(r, 1000)
onethousandwon, usd1 = divmod(r, 1000)
print(fiftythousandwon, tenthousandwon, onethousandwon)
# 변수지정 > 위치에 따라 각 값을 삽입
x = 996
y = 8
q = x//y
r = x%y
print(x, y, q, r)
print('{}를 {}로 나누면 몫은 {}이고 나머지는 {}입니다.'.format(x,y,q,r))
print('%s를 %s로 나누면 몫은 %s이고 나머지는 %s니다.' %(x,y,q,r))
# %s = 문자열format
print('%d를 %d로 나누면 몫은 %d이고 나머지는 %d니다.' %(x,y,q,r))x = 996
y = 8
q, r = divmod(x, y)
print(x, y, q, r)
print('{}를 {}로 나누면 몫은 {}이고 나머지는 {}입니다.'.format(x,y,q,r))
print('%s를 %s로 나누면 몫은 %s이고 나머지는 %s입니다.' %(x,y,q,r))
print('%d를 %d로 나누면 몫은 %d이고 나머지는 %d입니다.' %(x,y,q,r))
# 원주율 출력해보기
x = 3.141592
print('원주율은 {}'.format(x))
print('원주율은 %s' %(x))
# %s = 문자형 format
print('원주율은 %d' %(x))
# %d = 정수형 format
print('원주율은 %f' %(x))
# %f = 실수형 format
'원주율은 {}'.format(x)
# 오류
v_str = "대한민국
짝짝짝"
# 다음 줄로 입력했을 때에도 출력하게
v_str = """대한민국
짝짝짝"""
v_str = '''대한민국
짝짝짝'''
# escape code -> \n : 줄바꿈(enter key)
v_str = '대한민국 \n짝짝짝'
print(v_str)
# \t : tab key
v_str = '대한민국 \t짝짝짝'
print(v_str)
# \0 : null
v_str = '대한민국\0짝짝짝'
print(v_str)
# \' : 문자로 인식
v_str = '대한민국 \'짝짝짝\''
print(v_str)
# "문자'열'"
v_str = "대한민국 '짝짝짝'"
print(v_str)
# '문자"열"'
v_str = '대한민국 "짝짝짝"'
print(v_str)
# 문자 + 문자 = 문자. 연결연산자와 동일(오버로딩 기술)
x = "이름"
y = "파이썬개발자"
x + y
# 오류발생
# 문자 + 숫자 = 불가능
x + 100
# 문자 + 문자 = 가능
x + ' SQL 개발자,' + ' PL/SQL 개발자, ' + y
# 문자 * 숫자 = 복사(반복)
# PL/SQL or SQL = FOR문
(' ' + x + ' 오라클 엔지니어 ') * 10
# 비교연산자
# 변수 = (할당연산자)값
# PL/SQL 변수 := (할당연산자)값
x = 1
y = 2
x == y # 같다 == VS =
x > y #크다
x >= y #크거나 같다
x < y # 작다
x <= y # 작거나 같다
x != y # 같지 않다
# bool형 자료형 : false, true
type(x == y)
type(x != y)
x = True
y = False
type(x)
# 논리연산자(소문자) : and, or, not
(단, 소문자로 작성할 것)
True and True
True and False
True or True
True or False
not True
not False
# 인덱싱(indexing), 위치, 변수[위치(index)]
x = '오라클엔지니어'
# 0 1 2 3 4 5 6 : 양의 위치
# -7-6-5-4-3-2-1 : 음의 위치
x[0]
x[1]
x[5]
x[-1] # 제일 뒤에 값(위치)
x[-7]
# 슬라이싱(slicing), 텍스트 문자 분석할 때 이용
# 변수[시작인덱스:종료인덱스-1]
x = '오라클엔지니어'
# 0 1 2 3 4 5 6 : 양의 위치
# -7-6-5-4-3-2-1 : 음의 위치
x[0:2]
x[3:]
x[4:-5]
x[2:-1]
# 인덱싱(indexing), 위치, 변수[위치(index)]
x = '오라클엔지니어'
# 0 1 2 3 4 5 6 : 양의 위치
# -7-6-5-4-3-2-1 : 음의 위치
x[0]
x[1]
x[5]
x[-1] # 제일 뒤에 값(위치)
x[-7]
# 슬라이싱(slicing), 텍스트 문자 분석할 때 이용
# 변수[시작인덱스:종료인덱스-1]
x = '오라클엔지니어'
# 0 1 2 3 4 5 6 : 양의 위치
# -7-6-5-4-3-2-1 : 음의 위치
x[0:2]
x[3:]
x[4:-5]
x[2:-1]
x = '0123456789'
x[:]
# [시작인덱스:종료인덱스:증가분]
x[::1]
x[::2]
x[::3]
x[1::3]
x[1:7:2]
x[::-1] # 역순 출력
# 오류발생 및 수정 불가
x = "파리썬"
x[1] = '이' # 인덱스번호를 이용해서 문자를 수정할 수 없다.
x[0] + '이' + x[2]
# 함수는 미리보기용으로 가능, 지정해주기 위해서는 앞에 지정해줄 변수명을 작성해줘야 한다.
# 변수명.replace : 문자를 치환하는 함수
x = x.replace('리', '이')
x
# 변수명.startswith('문자') : 원본 문자열이 입력한 문자로 시작되는지 체크하는 함수
x = 'hello world'
x[0] == 'h'
x.startswith('h')
x[0] == 'H'
x.startswith('H')
# 변수명.endswith('문자') : 원본 문자열이 입력한 문자로 끝나는지 체크하는 함수
x[-1] == 'd'
x.endswith('d')
x[-2:] == 'ld'
x.endswith('ld')
# 변수명.find : 원본 문자열에서 입력한 문자가 존재하는 위치(인덱스)를 리턴하는 함수 ex)오류찾을때 활용
# PL/SQL = instr, substr, ike 연산자
x.find('w')
x[x.find('w')]
# 찾는 문자열이 없으면 -1 로 리턴
x.find('W')
# find(찾는문자열, 시작인덱스(0:기본값))
x.find('o') # 같은 문자가 있다면, 처음으로 나오는 위치로 리턴
x.find('o', 0)
x.find('o', 5)
x.find('o', 8)
x = 'hello world'
x.index('o')
x.index('o', 5)
x.index('o', 8) # 찾는 문자열이 없으면 오류발생
# 변수명.find vs 변수명.index : 큰 차이점) 찾는 문자열이 없으면 오류확인 가능
x.find('z')
x.index('z')
# 변수에 찾는 문자열이 있으면 True, 없으면 False
x.find('o') > 0
x.find('z') > 0
# in 연산자
'o' in x # 해당 문자가 있으면 true
'z' in x
# 대문자로 변환하는 함수
# PL/SQL 과 동일
x.upper()
# 소문자로 변환하는 함수
# PL/SQL 과 동일
x.lower()
# 변수명.capitalize() vs 변수명.title()
# 문장을 기준으로 첫글자 대문자 나머지는 소문자로 리턴
x.capitalize()
# 공백문자를 기준으로 첫글자 대문자 나머지는 소문자로 리턴
x.title()
# 변수명.swapcase() : 대문자 -> 소문자, 소문자 -> 대문자로 변환하는 함수
x.swapcase()
# SQL : rpad, lpad 연산자
# .center(), .ljust(), .rjust() : 자리수를 고정시킨 후 중앙, 왼쪽, 오른쪽에 배치하는 한수
x.center(20)
x.ljust(20)
x.rjust(20)
x.center(20).replace(' ', '#').upper()
# SQL : trim 연산자
# .strip() : 양쪽, 오른쪽, 왼쪽 공백을 제거하는 함수
x = ' hello '
x.strip()
x.lstrip()
x.rstrip()
# 기본값
x.strip(' ')
x.lstrip(' ')
x.rstrip(' ')
# 접두(앞, 왼쪽), 접미(뒤, 오른쪽) 연속되는 문자 제거
x = 'wwhelloww'
x.strip('w')
x.lstrip('w')
x.rstrip('w')
# 변수명.isalpha() : 문자열안에 알파벳, 한글로 이루어져있는지 확인하는 함수. True or False
x = 'hello'
y = 'hello2023'
z = '안녕하세요'
x.isalpha()
y.isalpha()
z.isalpha()
# 변수명.isalnum() : 문자열안에 알파벳, 한글, 숫자로 이루어져있는지 확인하는 함수. True or False
x.isalnum()
y.isalnum()
z.isalnum()
# 변수명.isnumeric() : 문자열안에 숫자로 이루어져있는지 확인하는 함수. True or False
x.isnumeric()
y.isnumeric()
z.isnumeric()
# 숫자 '0' , 대문자 'O' 의 차이를 찾을때
x = 'O1234'
x.isnumeric()
x = '01234'
x.isnumeric()
# .split : 특정한 문자열을 기준으로 분할하는 함수
x = 'hello,world'
x.split(',')
type(x.split(','))
x = 'hello world'
z = x.split(' ')
type(z)
z[0]
z[1]
# abc -> a,b,c 변환 -> 최종출력 : 'a' 'b' 'c'
# '특수문자'.join() : 문자열 사이사이에 특정한 문자를 붙이는 함수
x = 'abc'
x[0] + ',' + x[1] + ',' + x[2]
','.join(x)
' '.join(x)
' '.join(x).split()'Language > Python' 카테고리의 다른 글
| 231115 Python 함수 (1) | 2023.11.20 |
|---|---|
| 231115 Python_for문, range() (1) | 2023.11.20 |
| 231114 Python_자료형, 튜플(tuple), dictionary, 집합(set), bool(참,거짓), 조건제어문(if), 반복문(for, while) (1) | 2023.11.20 |
| 231113 Python의 특징 및 사용법 (0) | 2023.11.13 |
| 231113_Python 환경설정 및 설치 (1) | 2023.11.13 |