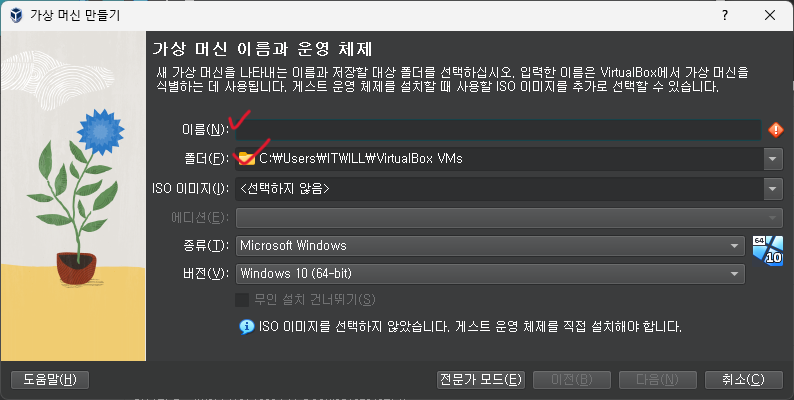
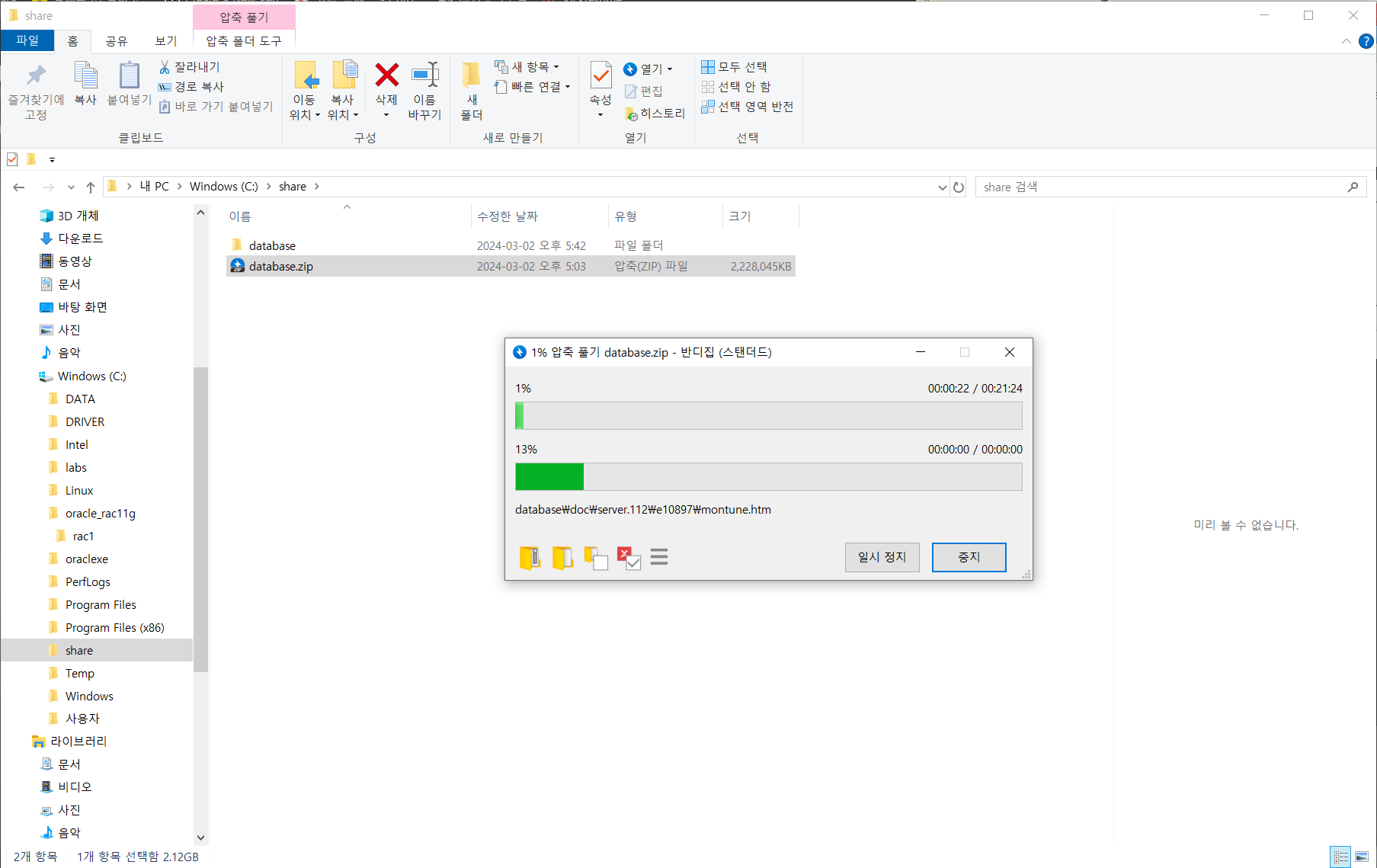
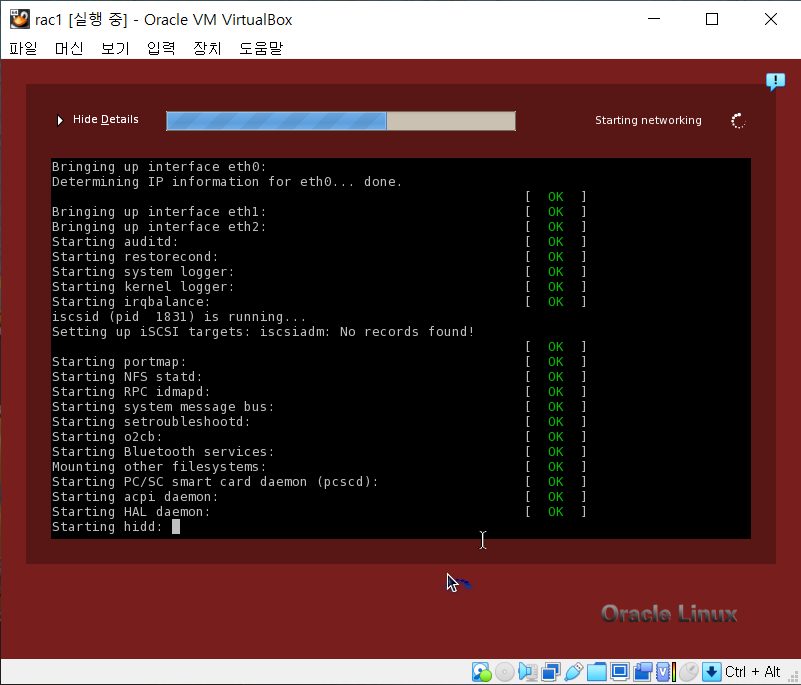
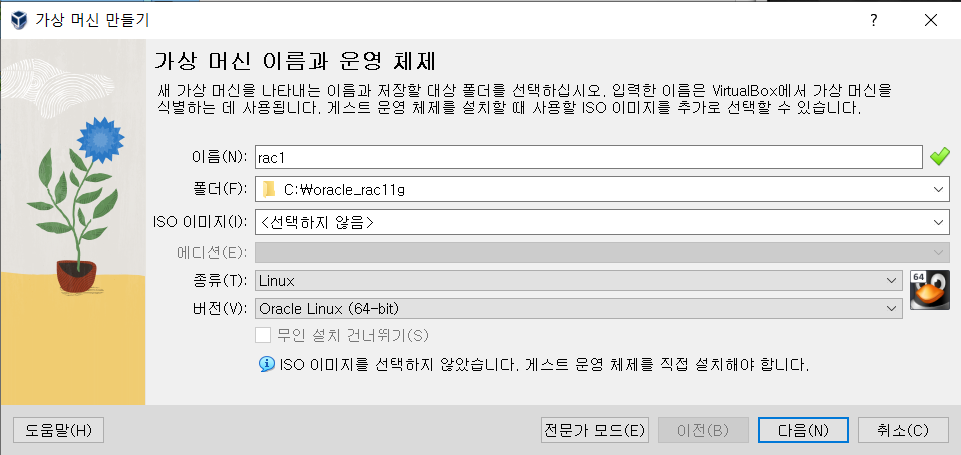
#) host 추가 [root@centos ~]# vi /etc/hosts 192.168.56.10 centos #) 방화벽 해제 및 리스트 확인 [root@centos ~]# iptables -F [root@centos ~]# iptables -L #) hostname 확인 및 변경 [root@centos ~]# hostnamectl [root@centos ~]# hostnamectl set-hostnmae centos #) JDK 설정 [root@centos ~]# mkdir -p /usr/java [root@centos ~]# ls anaconda-ks.cfg Downloads Music Templates Desktop initial-setup-ks.cfg Pictures Videos Documen..