93. 일반 테이블 생성하기(CREATE TABLE)
-- 예제93. 오라클에 데이터를 저장할 테이블을 다음과 같이 생성하시오
create table emp93
( empno number(10) ,
ename varchar2(10) ,
sal number(10, 2) , -- 숫자 10 자리를 허용하되 소숫점 두자리 허용
hiredate date ) ;
select * from emp93 ;
insert into emp93
values( 7788, 'scott', 3000, to_date('81/12/21', 'RR/MM/DD') );
drop table emp93 ;
-- 예제93_문제1. 다음의 테이블을 생성하세요.
/* 테이블명 : emp50 , 컬럼명 : empno, ename, sal, job, dpetno */
create table emp50
( empno number(10) ,
ename varchar2(10) ,
sal number(10, 2) ,
job varchar2(10) ,
deptno number(10) ) ;
select * from emp50 ;
insert into emp50
values ( 2912, 'SCOTT', 3000, 'salesman', 20) ;
94. 임시 테이블 생성하기(CREATE TEMPORAY TABLE)
-- 예제94. 다음과 같이 테이블을 만들고 데이터를 저장하는데 commit을 하면 데이터가 사라지게 하세요
create global temporary table emp37
( empno number(10) ,
ename varchar2(10) ,
sal number(10) )
on commit delete rows ;
insert into emp37 values (1111, 'scott', 3000) ;
insert into emp37 values(2222, 'smith', 4000) ;
select * from emp37 ;
commit ;
/*
1. on commit delete rows : 커밋을 하면 데이터를 지워라
2. on commit preserves rows : 세션을 종료하면 데이터를 지워라
*/
-- 예제94_문제1. 세션을 종료하면 데이터가 사라지는 임시테이블을 다음과 같이 생성하세요.
/* 테이블명 : emp94, 컬럼명 : empno, ename, sal */
create global temporary table emp94
( empno number(10) ,
ename varchar2(10) ,
sal number(10) )
on commit preserve rows ;
insert into emp94 values ( 1234, 'scott', 1234 );
insert into emp94 values ( 5678, 'smith', 5678 );
select * from emp94 ;
commit ;
95. 복잡한 쿼리를 단순하게 하기 ①(VIEW)
/* VIEW1 : 보안 */
-- 예제95. 사원테이블에서 직업이 SALESMAN 인 사원들의 사원번호, 사원이름, 직업, 관리자번호, 부서번호만 바라볼 수 있는 VIEW 를 만드세요.
create view emp_view
as
select empno, ename, sal, job, deptno
from emp
where job = 'SALESMAN' ;
select * from emp_view ;
update emp_view
set sal = 0
where ename = 'MARTIN' ;
select * from emp where ename = 'MARTIN' ;
rollback ;
-- 예제95_문제1. 사원테이블에서 부서번호가 20번인 사원들의 사원번호와 사원이름, 직업, 월급을 볼 수 있는 VIEW 를 생성하세요.
create view emp_view1
as
select empno, ename, job, sal
from emp
where deptno = 20 ;
select * from emp_view1 ;
96. 복잡한 쿼리를 단순하게 하기 ②(VIEW)
/* VIEW2 : 복잡한 쿼리문을 간단하게 검색 */
-- 예제96. 사원테이블에서 부서번호와 부서번호별 평균월급만 바라볼 수 있는 VIEW를 만드세요.
create view emp_view2
as
select deptno, round( avg(sal) ) as avgsal -- 그룹함수를 사용할 때에는 컬럼 별칭을 써야 테이블이 생성이 된다.
from emp
group by deptno ;
select * from emp_view2 ;
-- 예제96_문제1. 직업, 직업별 토탈월급을 출력하는 view 를 emp_view96 으로 생성하세요
create view emp_view96
as
select job, sum(sal) as sumsal
from emp
group by job ;
select * from emp_view96 ;
97. 데이터 검색 속도를 높이기(INDEX)
/* INDEX(객체) ; 예시) 목차 */
-- 예제97. 월급이 3000 인 사원의 이름과 월급을 인덱스를 통해서 빠르게 검색하세요.
explain plan for
select ename, sal
from emp
where sal = 3000 ;
select * from table(dbms_xplan.display) ; -- 실핼 계획
create index emp_sal -- 이름을 생성해줘야 함.
on emp(sal) ;
explain plan for
select ename, sal
from emp
where sal = 3000 ;
select * from table(dbms_xplan.display) ; -- 실핼 계획
select rowid, empno, ename -- rowid 는 행의 주소라고 함
from emp ;
select sal, rowid
from emp
where sal >= 0 ; -- index 볼때 조건식 : 숫자 >= 0 / 문자 > ' ' 형식으로 표현
-- 예제97_문제1. 사원테이블에 직업의 index를 생성하세요.
create index emp_job
on emp(job) ;
select ename, job
from emp
where job = 'PRESIDENT' ;
98. 절대로 중복되지 않는 번호 만들기(SEQUENCE)
-- 예제 98번. 사원번호에 번호를 입력할 때 데이터가 중복되지 않고 순서대로 입력되게 하시오
create sequence seq1 ;
select seq1.nextval
from dual ;
create sequence seq2
start with 1 -- 1부터 시작
maxvalue 100 -- 최대 100 까지
increment by 1 -- 1씩 증가
nocycle ; -- 100까지 간 이후로 회전하지 않겠다는 의미
select seq2.nextval
from dual ;
create sequence seq3
start with 1
maxvalue 100
increment by 1 ;
create table emp500 (
empno number(10) ,
ename varchar2(10)
) ;
insert into emp500 values (seq3.nextval, 'scott') ;
insert into emp500 values (seq3.nextval, 'smith') ;
insert into emp500 values (seq3.nextval, 'king') ;
select * from emp500 ;
-- 예제 98번_문제1번. dept 테이블에 부서번호 50번부터 입력하고 10 씩 증가되는 시퀀스를 생서하시오. (시퀀스 이름은 dept_seq1)
create sequence dept_seq1
start with 50
increment by 10 ;
insert into dept (deptno, dname, loc)
values ( dept_seq1.nextval, 'transfer', 'seoul') ;
select * from dept ;
99. 실수로 지운 데이터 복구하기 ①(FLASHBACK QUERY)
-- 예제 99. 사원 테이블을 지우기 전인 5분 전의 사원 테이블의 상태를 검색하세요
select * from emp ;
delete from emp ;
commit ;
rollback ;
select * from emp ;
insert into emp
select *
from emp
as of timestamp(systimestamp - interval '5' minute) ;
-- 예제 99_문제1. 사원 테이블의 월급을 모두 0 으로 변경하고 commit 한 후에 사원 테이블을 1분전 상태로 되돌리시오.
update emp
set sal = 0 ;
commit ;
select * from emp ;
select *
from emp
as of timestamp( systimestamp - interval '1' minute) ;
merge into emp e
using
( select empno, sal
from emp as of timestamp( systimestamp - interval '1' minute)
) s
on ( e.empno = s.empno )
when matched then
update set e.sal = s.sal ;
select * from emp ;
commit;
100. 실수로 지운 데이터 복구하기 ②(FLASHBACK TABLE)
/* FLASHBACK TABLE */
-- 예제 100. 사원 테이블을 지우기전인 5분전의 상태로 되돌리세요.
select *
from emp;
delete from emp ;
commit;
select * from emp ;
rollback ;
select * from emp ;
alter table emp enable row movement ;
flashback table emp to timestamp( systimestamp - interval '5' minute) ;
select *
from emp ;
commit;
select *
from emp ;
-- 예제 100_문제1. 사원 테이블의 월급을 전부 0 으로 변경하고 commit 한 다음에 사원 테이블의 월급을 전부 0 으로 변경하지 전 상황으로 복구하시오.
select *
from emp ;
update emp
set sal = 0 ;
commit ;
select *
from emp ;
rollback ;
select *
from emp ;
flashback table emp to timestamp( systimestamp - interval '5' minute) ;
select *
from emp;
commit;
101. 실수로 지운 데이터 복구하기 ③(FLASHBACK DROP
/* FLASHBACK BACK */
-- 예제101. drop 하면 휴지통으로 들어가요
select *
from emp ;
drop table emp ;
select * from emp ;
select *
from user_recyclebin
order by droptime desc ;
flashback table emp to before drop ; -- 최근에 drop된 table을 복구함
select * from emp ;
purge recyclebin ; -- 휴지통 비우기
select * from user_recyclebin ;
-- 예제101_문제1. dept 테이블을 drop 하고 다시 복구하세요.
select *
from dept ;
drop table dept ;
select *
from user_recyclebin ;
select * from dept ;
flashback table dept to before drop ;
select * from dept ;
102. 실수로 지운 데이터 복구하기 ④(FLASHBACK VERSION QUERY)
-- 예제102. 그동안 emp 테이블이 어떻게 변해왔는지 확인하고 싶다면?
SELECT systimestamp FROM dual;
select * from emp where ename = 'KING' ;
update emp
set sal = 0
where ename = 'KING' ;
COMMIT ;
delete from emp ;
COMMIT ;
SELECT ename, sal, deptno, versions_starttime, versions_endtime, versions_operation -- versions구절 을 사용하고 싶다면
FROM emp
VERSIONS BETWEEN TIMESTAMP TO_TIMESTAMP('23/09/29 23:00:33', 'RRRR-MM-DD HH24:MI:SS') AND MAXVALUE -- versions 절을 사용해줘야 한다. 변경된 시간을 써야 한다.
WHERE ename = 'KING'
ORDER BY versions_starttime nulls first ;
-- 예제102_문제1. 부서테이블의 부서위치를 전부 seoul로 변경하고 dept 테이블이 그동안 어떻게 변경되어왔는지 확인하세요.
SELECT systimestamp FROM dual ;
SELECT * FROM dept;
UPDATE dept
SET loc = 'seoul' ;
COMMIT;
SELECT deptno, dname, loc, sumsal, cnt, versions_starttime, versions_endtime, versions_operation
FROM dept
VERSIONS BETWEEN TIMESTAMP TO_TIMESTAMP('23/09/29 23:00:33', 'RRRR-MM-DD HH24:MI:SS') AND MAXVALUE
ORDER BY versions_starttime nulls first ;
103. 실수로 지운 데이터 복구하기 ⑤(FLASHBACK TRANSACTION QUERY)
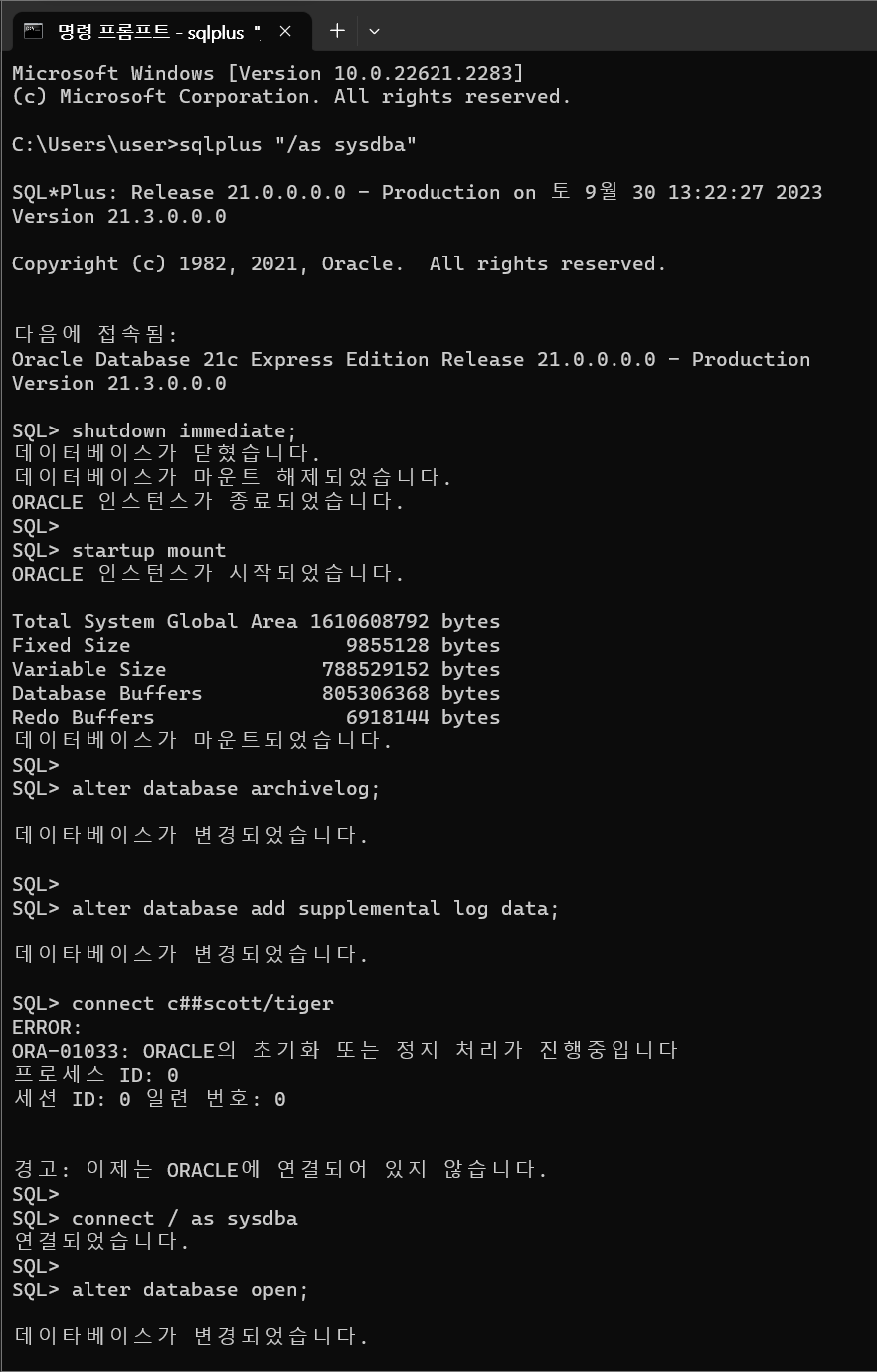
shutdown immediate : DB 내리기
startup mount
alter database archivelog; : DB 복구 모드
alter database add supplemental log data; : 복구에 필요한 스크립트를 저장
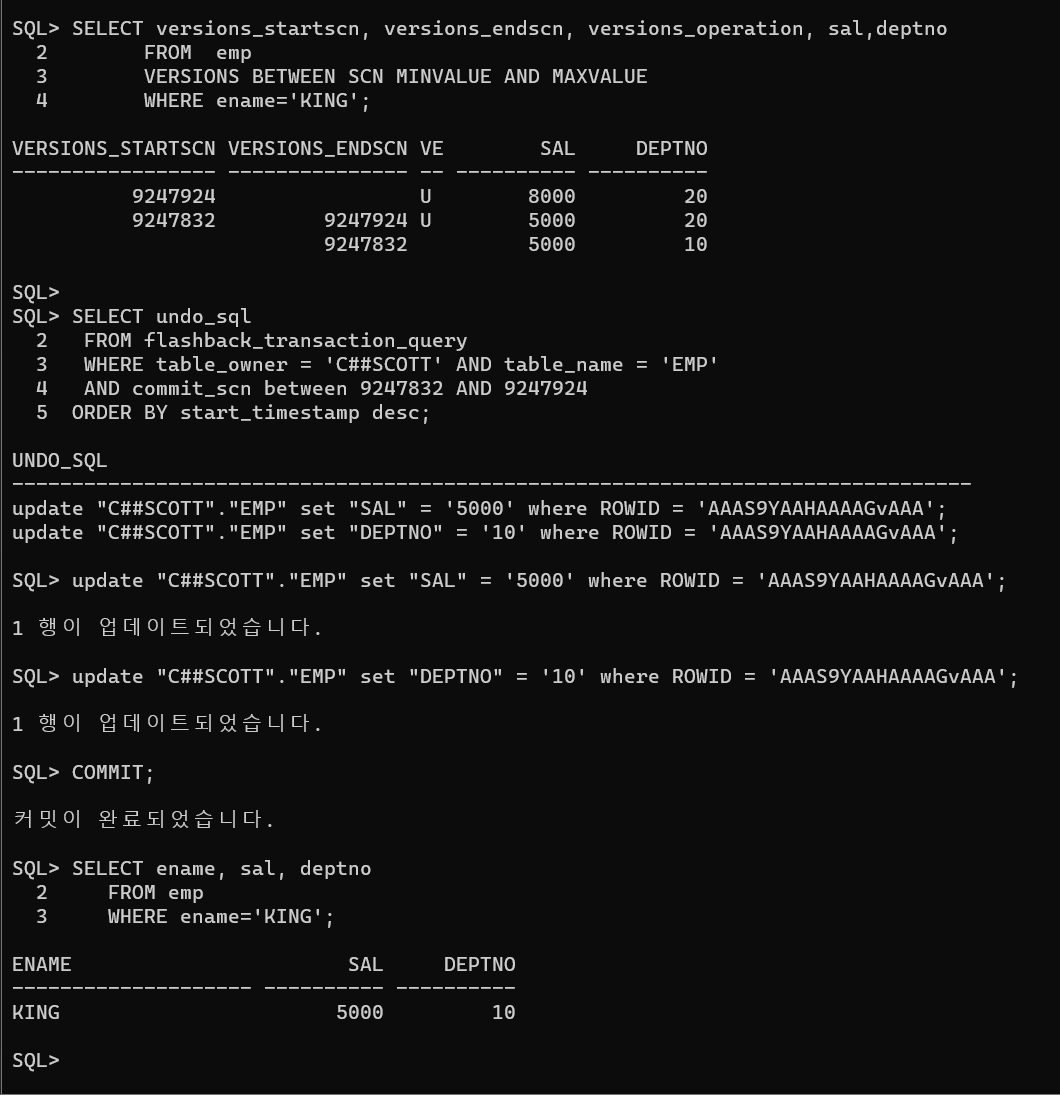
SQL> select versions_startscn, versions_endscn, versions_operation, sal, deptno
2 from emp
3 versions between scn minvalue and maxvalue
4 where ename='KING';
SELECT undo_sql
FROM flashback_transaction_query
WHERE table_owner = 'C##SCOTT' AND table_name = 'EMP'
AND commit_scn between 9247832 AND 9247924
ORDER BY start_timestamp desc;
104. 데이터의 품질 높이기 ①(PRIMARY KEY)
-- 예제 104. 사원번호에 중복된 데이터와 null 값을 입력안되게 하세요.
drop table dept2 ;
create table dept2 (
deptno number(10) constraint dept2_deptno_pk primary key, -- dept2_deptno_pk : 제약명
dname varchar2(10) ,
loc varchar2(10)
);
insert into dept2 values(10, 'aaa', 'bbb') ;
insert into dept2 values(20, 'aaa', 'bbb') ;
select *
from dept2 ;
insert into dept2 values(10, 'vvvv', 'www') ;
insert into dept2 values(null, 'ddk', 'aaa');
select table_name, constraint_name
from user_constraints
where table_name = 'DEPT2';
alter table dept2
drop constraint dept2_deptno_pk; -- 제약조건 삭제
alter table dept
add constraint dept_deptno_pk primary key(deptno) ;
select table_name, constraint_name
from user_constraints
where table_name = 'DEPT';
select *
from dept;
-- 예제 104_문제1. 사원 테이블의 empno를 primary key로 생성하시오.
alter table emp
add constraint emp_empno_pk primary key(empno) ;
105. 데이터의 품질 높이기 ②(UNIQUE)
/* UNIQUE */
/*
■ 제약을 생성하는 2가지 방법
1. 테이블을 생성할 때 제약을 걸면서 생성하는 방법
2. 만들어진 테이블에 제약을 거는 방법
*/
-- 1. 테이블 생성할 때 제약을 걸면서 생성하는 방법 예제
-- 예제 105. 사원번호에 중복된 데이터가 입력안되게 하세요.
create table dept3
( deptno number(10) ,
dname varchar2(14) constraint dept3_dname_un unique , -- dept3_dname_un: 제약이름
loc varchar2(10)
);
select a.constraint_name, a.constraint_type, b.column_name
from user_constraints a, user_cons_columns b -- user_constraints: 테이블,제약조건 등의 정보 / user_cons_columns: 컬럼명
where a.table_name = 'DEPT3' -- 테이블명은 무조건 대문자로 작성해야 함.
and a.constraint_name = b.constraint_name ;
insert into dept3 values (10, 'ACCOUNTING', 'NEW YORK') ;
insert into dept3 values (20, 'RESEARCH', 'DALLAS');
insert into dept3 values (30, 'SALES', 'CHICAGO');
insert into dept3 values (40, 'OPEATIONS', 'BOSTON');
select * from dept3;
insert into dept3 values (50, 'RESEARCH', 'SEOUL');
drop table dept3;
-- 2. 만들어진 테이블에 제약을 거는 방법 예제
create table dept4 (
deptno number(10) ,
dname varchar2(13) ,
loc varchar2(10)
);
alter table dept4
add constraint dept4_dname_un unique(dname) ;
insert into dept4 values (10, 'ACCOUNTING', 'NEW YORK') ;
insert into dept4 values (20, 'RESEARCH', 'DALLAS');
insert into dept4 values (30, 'SALES', 'CHICAGO');
insert into dept4 values (40, 'OPEATIONS', 'BOSTON');
select * from dept4 ;
insert into dept4 values (50, 'RESEARCH', 'SEOUL');
/* 문제1. 사원번호, 사원이름, 월급, 직업을 담는 테이블을 아래와 같이 생성하는데
사원번호 컬럼에 중복된 데이터가 입력되지 않도록 제약을 걸어서 생성하세요.
테이블명 : emp1000 / 컬럼명 : empno, ename, sal, job */
create table emp1000 (
empno number(10) constraint emp1000_empno_un unique ,
ename varchar2(10) ,
sal number(10) ,
job varchar2(10)
);
insert into emp1000 values (1111, 'scott', 3000, 'salesman');
insert into emp1000 values (2222, 'allen', 5000, 'analyst');
insert into emp1000 values (1111, 'smith', 6000, 'analyst');
select * from emp1000;
-- 문제2. 사원테이블(emp)에 사원번호에 중복된 데이터가 있는지 검색해보세요.
select empno, count(*)
from emp
group by empno
having count(*) >= 2 ;
-- 문제3. 사원테이블(emp)에 사원번호에 중복된 데이터가 입력되지 못하도록 제약을 걸어보세요
alter table emp
add constraint emp_empno_un unique(empno) ;
106. 데이터의 품질 높이기 ③(NOT NULL)
/* NOT NULL */
-- 예제106. 사원이름에 NULL 입력안되게 하세요.
drop table dept5;
create table dept5 (
deptno number(10) ,
dname varchar2(14) ,
loc varchar2(10) constraint dept5_loc_nn not null
);
insert into dept5 values (10, 'ACCOUNTING', 'NEW YORK') ;
insert into dept5 values (20, 'RESEARCH', 'DALLAS');
insert into dept5 values (30, 'SALES', 'CHICAGO');
insert into dept5 values (40, 'OPEATIONS', null);
insert into dept5(deptno, dname) values (50, 'TRANSFER');
select * from dept5;
drop table dept6;
create table dept6 (
deptno number(10) ,
dname varchar2(13) ,
loc varchar2(10)
);
alter table dept6
modify loc constraint dept6_loc_nn not null;
insert into dept6 values (10, 'ACCOUNTING', 'NEW YORK') ;
insert into dept6 values (20, 'RESEARCH', 'DALLAS');
insert into dept6 values (30, 'SALES', 'CHICAGO');
insert into dept6 values (40, 'OPEATIONS', null);
insert into dept6(deptno, dname) values (50, 'TRANSFER');
select * from dept6;
-- 문제1. 사원테이블에 사원이름에 null 값이 몇건 존재하는지 검색하세요
select count(*)
from emp
where ename is null ;
-- 문제2. 사원 테이블에 사원 이름에 not null 제약을 거세요.
alter table emp
modify ename constraint emp_ename_nn not null ;
-- 문제3. 부서 테이블에 부서번호에 not null 제약을 거세요.
alter table dept
modify deptno constraint dept_deptno_nn not null ;
107. 데이터의 품질 높이기 ④(CHECK)
-- 예제107. 월급 컬럼에 9000 보다 큰 월급은 입력되지 못하게 하세요.
-- 1. 테이블 생성할 때 체크 제약 걸기
CREATE TABLE emp6 (
empno NUMBER(10),
ename VARCHAR2(20),
sal NUMBER(10) CONSTRAINT emp6_sal_ck CHECK ( sal BETWEEN 0 AND 6000 ) -- check(조건식)
);
INSERT INTO emp6 VALUES ( 7839, 'KING', 5000 );
INSERT INTO emp6 VALUES ( 7698, 'BLAKE', 2850 );
INSERT INTO emp6 VALUES ( 7782, 'CLAKE', 2450 );
INSERT INTO emp6 VALUES ( 7839, 'JONES', 2975 );
COMMIT;
SELECT * FROM emp6 ;
UPDATE emp6
SET sal = 9000
WHERE ename = 'CLARK';
INSERT INTO emp6 VALUES ( 7566, 'ADAMS', 9000 );
ALTER TABLE emp6
DROP CONSTRAINT emp6_sal_ck ;
INSERT INTO emp6 VALUES ( 7566, 'ADAMS', 9000 ) ;
-- 2. 만들어진 테이블에 체크제약 걸기
-- 사원테이블에 월급에 체크제약을 거는데 월급이 0 ~ 9000 사이의 데이터만 입력되겠금 하시오.
ALTER TABLE emp
ADD CONSTRAINT emp_sal_ck CHECK( sal BETWEEN 0 AND 9000 ) ;
insert into emp(empno, ename, sal) values (1111, 'smith', 9500) ;
update emp
set sal = 9600
where ename = 'KING' ;
-- 문제1. 사원테이블의 부서번호에 부서번호가 10, 20, 30번만 입력, 수정되겠금 체크제약을 거시오.
alter table emp
add constraint emp_deptno_ck check(deptno in (10, 20, 30) ) ;
-- 문제2. 부서테이블의 부서위치에 NEW YORK, DALLAS, CHICAGO, BOSTON 만 입력, 수정되겠금 체크제약을 거시오.
alter table dept
add constraint dept_loc_ck check(loc in('NEW YORK', 'DALLAS', 'CHICAGO', 'BOSTON') ) ;
-- 문제3. 사원 테이블에 이메일 컬럼을 다음과 같이 추가하고 이메일에 @ 가 있어야지만 데이터가 입력 또는 수정 되겠금 체크제약을 거시오
alter table emp
add email varchar2(50) ;
select * from emp ;
alter table emp
add constraint emp_email_ck check(email like '%@%' ) ;
insert into emp values (1111, 'SOHEE', 'MANGER', 1234, sysdate, 6000, null, 10, 'admin@admin.com');
108. 데이터의 품질 높이기 ⑤(FOREIGN KEY)
/* FOREIGN KEY */
-- 예제108. 부서테이블에 있는 부서번호만 사원 테이블에 입력되게 하려면?
create table dept7 (
deptno number(10) constraint dept7_deptno_pk primary key ,
dname varchar2(14) ,
loc varchar2(10)
);
create table emp7 (
empno number(10) ,
ename varchar2(20) ,
sal number(10) ,
deptno number(10) constraint emp7_deptno_fk references dept7(deptno)
);
select a. constraint_name, a.constraint_type, b.column_name
from user_constraints a, user_cons_columns b
where a.table_name in ('DEPT7', 'EMP7')
and a.constraint_name = b.constraint_name ;
/* dept 데이터를 dept7 에 넣기*/
insert into dept7
select deptno, dname, loc
from dept;
select * from dept7 ;
/* emp 테이블 데이터를 emp7 에 넣기*/
insert into emp7
select empno, ename, sal, deptno
from emp;
select * from dept7 ;
select * from emp7 ;
insert into emp7 values (1111, 'jack', 3000, 80 );
/* primary key 삭제 하기 */
alter table dept7
drop constraint dept7_deptno_pk ; -- 오류발생 : primary key 가 있어 삭제가 되지 않는다.
alter table dept7
drop constraint dept7_deptno_pk cascade; -- cascade: pk와 fk 모두 삭제가 된다.
select a. constraint_name, a.constraint_type, b.column_name
from user_constraints a, user_cons_columns b
where a.table_name in ('DEPT7', 'EMP7')
and a.constraint_name = b.constraint_name ;
-- 문제1. 사원테이블에 empno 에 primary key 를 거시오.
alter table emp
add constraint emp_empno_pk primary key(empno) ;
/* 문제 2. 사원테이블에 관리자 번호(mgr)에 foreign key 제약을 걸고 사원테이블에 사원번호에 있는 컬럼을 참조하게 하여
관리자 번호가 사원 테이블에 있는 사원번호에 해당하는 사원들만 관리자번호로 입력 또는 수정될 수 있도록 하시오. */
alter table emp
add constraint emp_empno_fk foreign key(mgr) references emp(empno) ;
109. WITH절 사용하기 ①(WITH ~ AS)
-- 예제109. 시간이 오래걸리는 무거운 쿼리문이 하나의 쿼리문에서 반복 사용된다면?
SELECT job, SUM(sal) AS 토탈
FROM emp
GROUP BY job;
SELECT job, SUM(sal) AS 토탈
FROM emp
GROUP BY job
HAVING SUM(sal) > ( SELECT AVG( SUM(sal) )
FROM emp
GROUP BY job );
WITH job_sumsal AS ( SELECT job, SUM(sal) AS 토탈 -- job_sumsal : 테이블명
FROM emp
GROUP BY job)
SELECT job, 토탈
FROM job_sumsal
WHERE 토탈 > ( SELECT AVG(토탈)
FROM job_sumsal );
-- 문제1. 부서번호별 토탈월급을 출력하는데 부서번호별 토탈월급들의 평균값 보다 더 큰것만 출력되게 하세요.
WITH dept_sumsal AS ( SELECT deptno, sum(sal) as sumsal
FROM emp
GROUP BY deptno )
SELECT deptno, sumsal
FROM dept_sumsal
WHERE sumsal > ( SELECT AVG(sumsal)
FROM dept_sumsal ) ;
-- 문제2. 부서위치, 부서위치별 토탈월급을 출력하는데 부서위치별 토탈월급의 평균값보다 더 큰 값만 출력하시오.
with loc_sumsal as ( select loc, sum(sal) as sumsal
from emp natural join dept
group by loc )
select loc, sumsal
from loc_sumsal
where sumsal > ( select avg(sumsal)
from loc_sumsal ) ;
110. WITH절 사용하기 ②(SUBQUERY FACTORING)
-- 예제110. 아래의 쿼리문은 실행이 될까요?
/* select deptno, sum(sal)
from ( select job, sum(sal) 토탈
from emp
group by job) as job_sumsal ,
( select deptno, sum(sal) 토탈
from emp
group by deptno
having sum(sal) > ( select avg(토탈) +3000 )
from job_sumsal )
); */
select job, sum(sal) 토탈
from emp
group by job;
select deptno, sum(sal) 토탈
from emp
group by deptno ;
WITH JOB_SUMSAL AS ( SELECT JOB, SUM(SAL) 토탈
FROM EMP
GROUP BY JOB ) ,
DEPTNO_SUMSAL AS ( SELECT DEPTNO, SUM(SAL) 토탈
FROM EMP
GROUP BY DEPTNO
HAVING SUM(SAL) > ( SELECT AVG(토탈) + 3000
FROM JOB_SUMSAL )
)
SELECT DEPTNO, 토탈
FROM DEPTNO_SUMSAL ;
-- 문제1. 입사한 년도와 입사한 년도별 토탈월급을 출력하는데 부서번호별 토탈월급들의 평균값보다 더 큰것만 출력하시오.
with deptno_sumsal as ( select deptno, sum(sal) 토탈
from emp
group by deptno ) ,
hire_sumsal as ( select to_char(hiredate, 'RRRR') hire_year, sum(sal) 토탈
from emp
group by to_char(hiredate, 'RRRR')
having sum(sal) > ( select avg(토탈)
from deptno_sumsal )
)
select hire_year, 토탈
from hire_sumsal ;'SQL 기초 실무 > 중급편Ⅰ, Ⅱ' 카테고리의 다른 글
| 23.09.25. SQL Developer 예제 88 ~ 92번 (0) | 2023.09.28 |
|---|---|
| 23.09.25. SQL Developer 예제 78 ~ 87번 (0) | 2023.09.28 |
| 23.09.22. SQL Developer 예제 67 ~ 77번 (0) | 2023.09.27 |
| 23.09.20. SQL Developer 예제 56 ~ 66번 (0) | 2023.09.20 |