FTP 설치 후 호스트ip 사용자명 비밀번호 포트 작성 후 '빠른 연결' 클릭
# csv 삽입
[user1@centos ~]$ ls
asia Documents emp.csv Hello.java new Public Templates test1 u01
Desktop Downloads Hello.class Music Pictures temp1 test test2 Videos
[user1@centos ~]$ head emp.csv
# emp.csv 원하는 단어 찾기
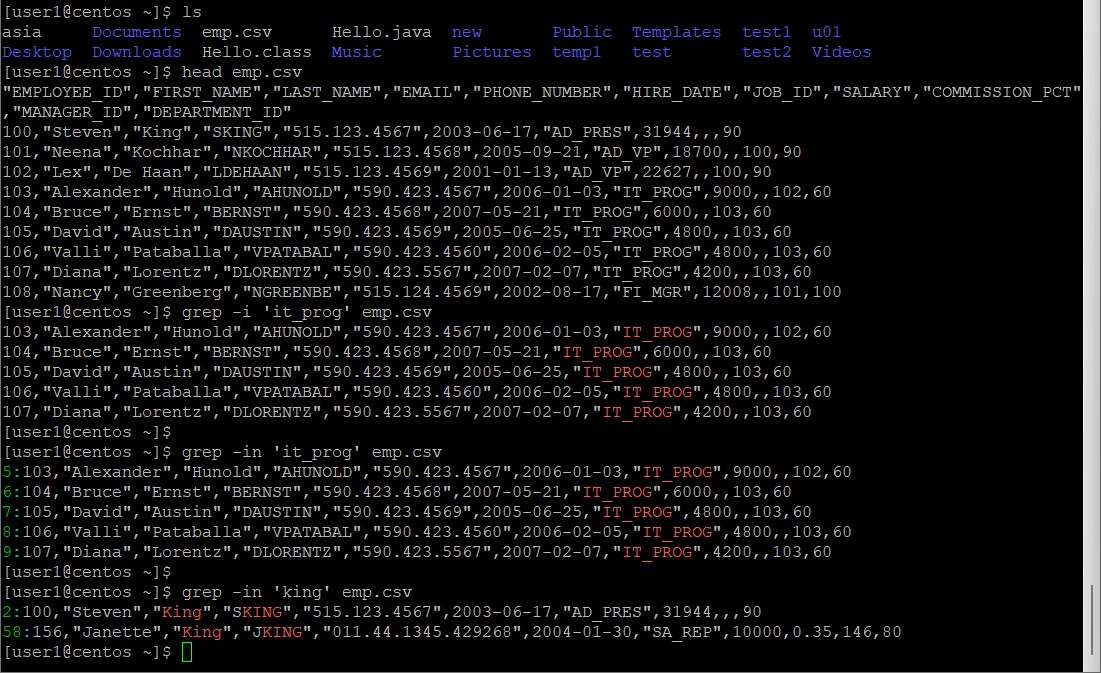
[user1@centos ~]$ grep -i 'it_prog' emp.csv
103,"Alexander","Hunold","AHUNOLD","590.423.4567",2006-01-03,"IT_PROG",9000,,102,60
104,"Bruce","Ernst","BERNST","590.423.4568",2007-05-21,"IT_PROG",6000,,103,60
105,"David","Austin","DAUSTIN","590.423.4569",2005-06-25,"IT_PROG",4800,,103,60
106,"Valli","Pataballa","VPATABAL","590.423.4560",2006-02-05,"IT_PROG",4800,,103,60
107,"Diana","Lorentz","DLORENTZ","590.423.5567",2007-02-07,"IT_PROG",4200,,103,60
[user1@centos ~]$ grep -in 'it_prog' emp.csv
5:103,"Alexander","Hunold","AHUNOLD","590.423.4567",2006-01-03,"IT_PROG",9000,,102,60
6:104,"Bruce","Ernst","BERNST","590.423.4568",2007-05-21,"IT_PROG",6000,,103,60
7:105,"David","Austin","DAUSTIN","590.423.4569",2005-06-25,"IT_PROG",4800,,103,60
8:106,"Valli","Pataballa","VPATABAL","590.423.4560",2006-02-05,"IT_PROG",4800,,103,60
9:107,"Diana","Lorentz","DLORENTZ","590.423.5567",2007-02-07,"IT_PROG",4200,,103,60
[user1@centos ~]$ grep -in 'king' emp.csv
2:100,"Steven","King","SKING","515.123.4567",2003-06-17,"AD_PRES",31944,,,90
58:156,"Janette","King","JKING","011.44.1345.429268",2004-01-30,"SA_REP",10000,0.35,146,80
[user1@centos ~]$ grep -in 'user' /etc/passwd
12:ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
16:polkitd:x:999:998:User for polkitd:/:/sbin/nologin
18:colord:x:997:994:User for colord:/var/lib/colord:/sbin/nologin
20:saned:x:996:993:SANE scanner daemon user:/usr/share/sane:/sbin/nologin
22:saslauth:x:994:76:Saslauthd user:/run/saslauthd:/sbin/nologin
27:radvd:x:75:75:radvd user:/:/sbin/nologin
30:qemu:x:107:107:qemu user:/:/sbin/nologin
31:tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
32:sssd:x:990:984:User for sssd:/:/sbin/nologin
33:usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
34:geoclue:x:989:983:User for geoclue:/var/lib/geoclue:/sbin/nologin
37:rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
38:nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
44:user1:x:1000:1000:user1:/home/user1:/bin/bash
46:user8:x:1005:1005::/home/user8:/bin/bash
■ cut : 문자열 자르기
[user1@centos ~]$ cat /etc/passwd
...
user1:x:1000:1000:user1:/home/user1:/bin/bash
...
[user1@centos ~]$ cat /etc/passwd | cut -d: -f1
...
user1
...
[user1@centos ~]$ cat /etc/passwd | cut -d: -f1 > users.txt
[user1@centos ~]$ cat emp.csv | cut -d, -f1,3,5,6
옵션
-d : 필드구분자
-f : 추출한 열
■ awk : 특정 단어가 들어가 있는 라인에서 특정 컬럼명을 출력하고자 할 때 사용하는 명령어
-F : 필드구분자
[user1@centos ~]$ awk -F: '{print $1,$3}' /etc/passwd
[user1@centos ~]$ awk -F, '{print $1,$3}' emp.csv
■ 연산자
1. 산술연산자 : +, -. *, /
2. 비교연산자 : =(==), !=., >, >=, <, <=
3. 논리연산자 : &&(and), ||(or), !(not)
행 제한 추출한 행
(WHERE절) (SELECT문)
awk -F, '$7=="IT-PROG" {print $1,$3,$7,$8}' emp.csv
[user1@centos ~]$ awk -F ',' '$7=="\"IT_PROG\"" {print $1,$3,$7,$8}' emp.csv

[user1@centos ~]$ awk -F, '{if($7=="\"IT_PROG\"") {print $1,$3,$7,$8}}' emp.csv

[user1@centos ~]$ awk -F ',' '{if($7 ~ "\"IT_PROG\"") {print $1,$3,$7,$8}}' emp.csv

[user1@centos ~]$ cat emp.csv | awk -F ',' '{if($7 ~ "\"IT_PROG\"") {print $1,$3,$7,$8}}'

[user1@centos ~]$ awk -F, '{print $1,$3,$7,$8}' emp.csv | grep -i 'it_prog'

[user1@centos ~]$ awk -F, '/IT_PROG/{print $1,$3,$7,$8}' emp.csv

[user1@centos ~]$ awk -F, '$8 >= 15000 {print $1,$3,$7,$8}' emp.csv

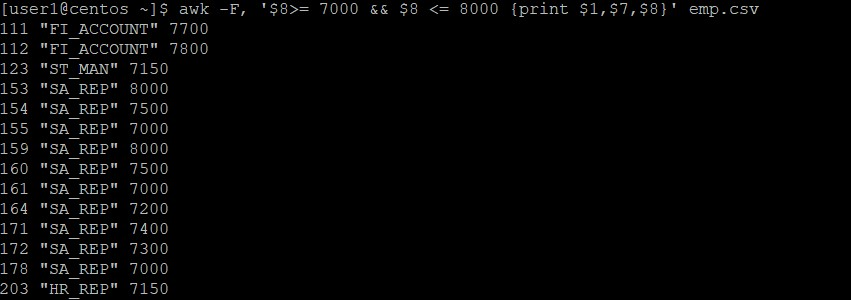
[user1@centos ~]$ awk -F, '$8>= 7000 && $8 <= 8000 {print $1,$7,$8}' emp.csv
# sum 연산작업
[user1@centos ~]$ awk -F, '{print $8}' emp.csv | awk '{sum += $1} END {print sum}'
729299
[user1@centos ~]$ ls -l | awk '{print $5}' | awk '{sum += $1} END {print sum}'
11492
[user1@centos ~]$ ls -l | awk '{print "파일 : "$9 " 용량 : " $5}'
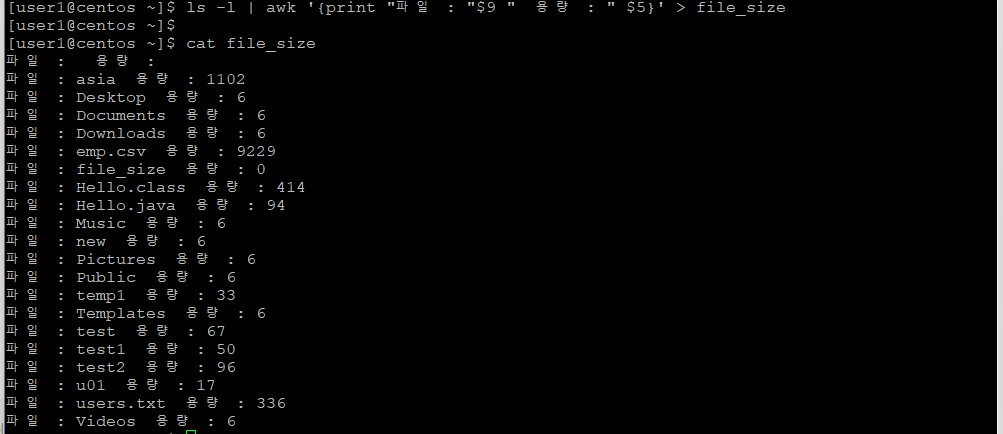
[user1@centos ~]$ ls -l | awk '{print "파일 : "$9 " 용량 : " $5}' > file_size
[user1@centos ~]$ cat file_size
[user1@centos ~]$ ls -l | awk '{print $5}' | awk '{sum += $1} END {print "총 용량:"sum}'
총 용량:12103
기준값 | 출력 |
ls -l | awk '{print $5}' | awk '{sum += $1} END {print "총 용량:"sum}'
■ sort
특정한 컬럼을 기준으로 정렬하는 명령어
sort -k 2 emp.csv
정렬 2번째필드
awk -F, '{print $3}' emp.csv
awk -F, '{print $3}' emp.csv | sort
# 오름차순
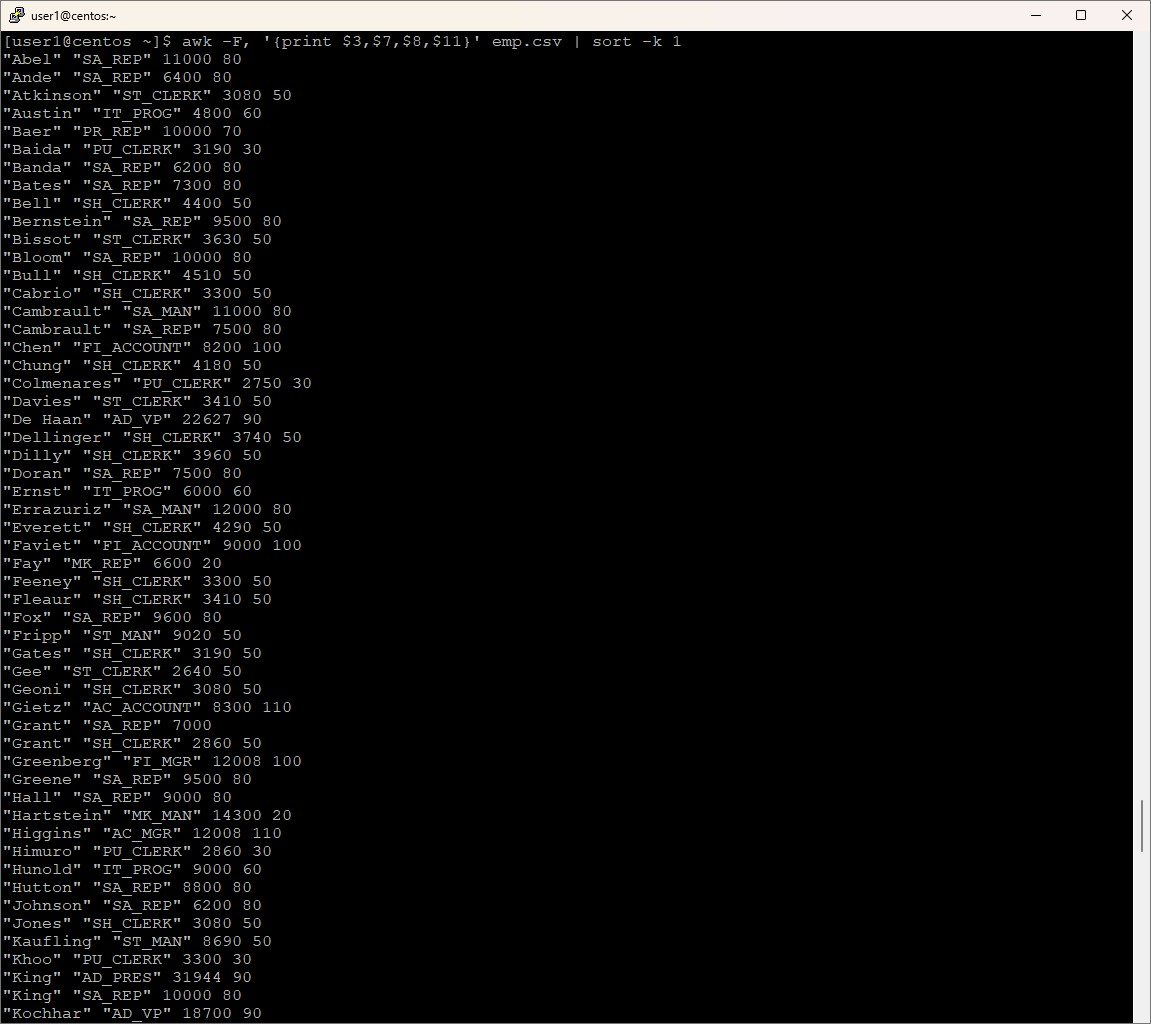
awk -F, '{print $3,$7,$8,$11}' emp.csv | sort -k 4
# 내림차순
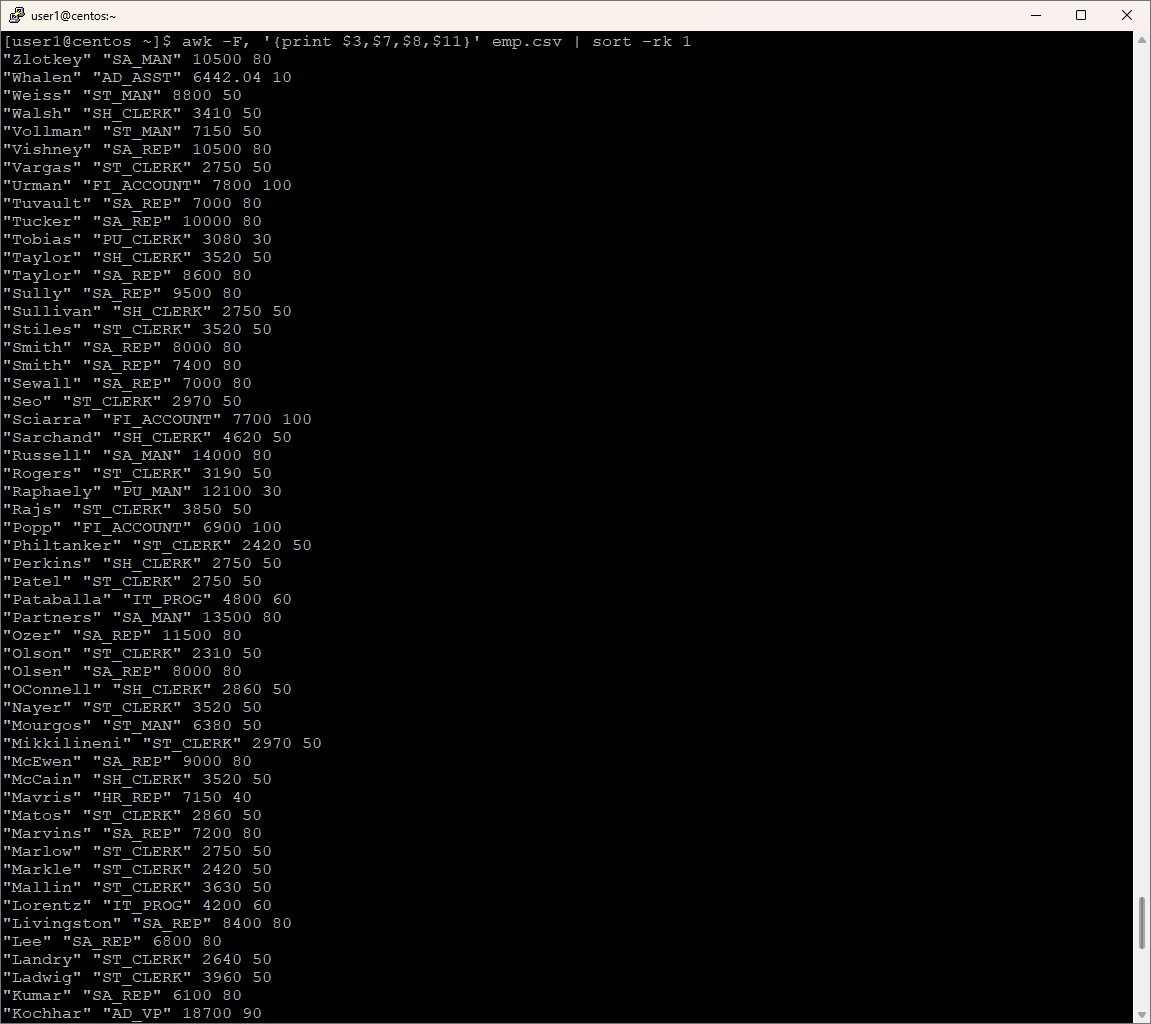
awk -F, '{print $3,$7,$8,$11}' emp.csv | sort -rk 1
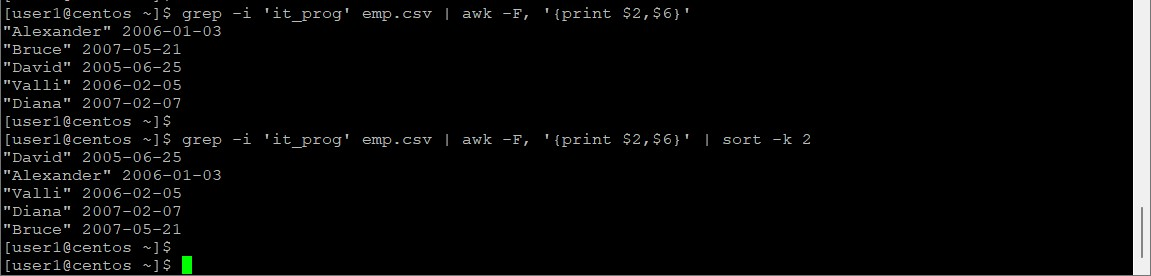
[user1@centos ~]$ grep -i 'it_prog' emp.csv | awk -F, '{print $2,$6}'
"Alexander" 2006-01-03
"Bruce" 2007-05-21
"David" 2005-06-25
"Valli" 2006-02-05
"Diana" 2007-02-07
[user1@centos ~]$ grep -i 'it_prog' emp.csv | awk -F, '{print $2,$6}' | sort -k 2
"David" 2005-06-25
"Alexander" 2006-01-03
"Valli" 2006-02-05
"Diana" 2007-02-07
"Bruce" 2007-05-21
■ uniq
중복된 라인을 제거하는 명령어
[user1@centos ~]$ awk -F, '{print $7}' emp.csv | uniq
"AD_PRES"
"AD_VP"
"IT_PROG"
"FI_MGR"
"FI_ACCOUNT"
"PU_MAN"
"PU_CLERK"
"ST_MAN"
"ST_CLERK"
"SA_MAN"
"SA_REP"
"SH_CLERK"
"AD_ASST"
"MK_MAN"
"MK_REP"
"HR_REP"
"PR_REP"
"AC_MGR"
"AC_ACCOUNT"
[user1@centos ~]$ awk -F, '{print $7}' emp.csv | uniq | sort
"AC_ACCOUNT"
"AC_MGR"
"AD_ASST"
"AD_PRES"
"AD_VP"
"FI_ACCOUNT"
"FI_MGR"
"HR_REP"
"IT_PROG"
"MK_MAN"
"MK_REP"
"PR_REP"
"PU_CLERK"
"PU_MAN"
"SA_MAN"
"SA_REP"
"SH_CLERK"
"ST_CLERK"
"ST_MAN"
■ echo(=printout)
출력하고자 하는 글자를 출력할 때 사용하는 명령어
[user1@centos ~]$ echo "오늘 하루도 수고하세요"
오늘 하루도 수고하세요
------------------------------------------------------------
<쓰기 연습>
#!/bin/bash
echo "********************************************"
echo -n "직업을 입력해주세요 : "
read job_name <- 입력변수
echo "********************************************"
grep -i $job_name emp.csv | awk -F, '{print $1,$3,$7}'
------------------------------------------------------------
[user1@centos ~]$ vi job.sh
[user1@centos ~]$ ls
asia Documents emp.csv Hello.class job.sh new Public Templates test1 u01 Videos
Desktop Downloads file_size Hello.java Music Pictures temp1 test test2 users.txt
[user1@centos ~]$
[user1@centos ~]$ sh job.sh
***********************************
직업을 입력해주세요 : it_prog
***********************************
103 "Hunold" "IT_PROG"
104 "Ernst" "IT_PROG"
105 "Austin" "IT_PROG"
106 "Pataballa" "IT_PROG"
107 "Lorentz" "IT_PROG"
[user1@centos ~]$ sh job.sh
***********************************
직업을 입력해주세요 : ad_vp
***********************************
101 "Kochhar" "AD_VP"
102 "De Haan" "AD_VP"
[user1@centos ~]$
[user1@centos ~]$ . job.sh
------------------------------------------------------------
<쓰기 연습>
#!/bin/bash
echo "***********************************"
echo -n "부서번호를 입력해주세요 : "
read deptid
echo "***********************************"
awk -F, '{print $2,$6,$7,$11}' emp.csv | grep $deptid
------------------------------------------------------------
[user1@centos ~]$ ls
asia Desktop emp.csv Hello.java new temp1 test1 users.txt Documents file_size job.sh Pictures Templates test2 Videos deptno.sh Downloads Hello.class Music Public test u01
[user1@centos ~]$ vi deptno.sh
[user1@centos ~]$ sh deptno.sh
***********************************
부서번호를 입력해주세요 : 80
***********************************
"John" "SA_MAN" 80
"Karen" "SA_MAN" 80
"Alberto" "SA_MAN" 80
"Gerald" "SA_MAN" 80
"Eleni" "SA_MAN" 80
"Peter" "SA_REP" 80
"David" "SA_REP" 80
"Peter" "SA_REP" 80
"Christopher" "SA_REP" 80
"Nanette" "SA_REP" 80
"Oliver" "SA_REP" 80
"Janette" "SA_REP" 80
...
"Jonathon" "SA_REP" 80
"Jack" "SA_REP" 80
"Charles" "SA_REP" 80
[user1@centos ~]$ sh deptno.sh
***********************************
부서번호를 입력해주세요 : 20
***********************************
"Steven" 2003-06-17 "AD_PRES" 90
"Neena" 2005-09-21 "AD_VP" 90
"Lex" 2001-01-13 "AD_VP" 90
"Alexander" 2006-01-03 "IT_PROG" 60
"Bruce" 2007-05-21 "IT_PROG" 60
"David" 2005-06-25 "IT_PROG" 60
"Valli" 2006-02-05 "IT_PROG" 60
...
"Hermann" 2002-06-07 "PR_REP" 70
"Shelley" 2002-06-07 "AC_MGR" 110
"William" 2002-06-07 "AC_ACCOUNT" 110
------------------------------------------------------------
<dept_no.sh>
#!(shebang) 셔뱅
#! 다음에 오는 문구를 실행한다.
#!/bin/bash
echo "***********************************"
echo -n "부서번호를 입력해주세요 : "
read deptid
echo "***********************************"
awk -F, -v v_id=$deptid '$11==v_id {print $2,$6,$7,$11}' emp.csv
------------------------------------------------------------
[user1@centos ~]$ vi dept_no.sh
[user1@centos ~]$ ls
asia Desktop emp.csv Hello.java new temp1 test1 users.txt
dept_no.sh Documents file_size job.sh Pictures Templates test2 Videos
deptno.sh Downloads Hello.class Music Public test u01
[user1@centos ~]$ sh dept_no.sh
***********************************
부서번호를 입력해주세요 : 10
***********************************
"Jennifer" 2003-09-17 "AD_ASST" 10
[user1@centos ~]$ sh dept_no.sh
[user1@centos ~]$ . dept_no.sh
# shell 호출방법
[user1@centos ~]$ sh dept_no.sh
[user1@centos ~]$ . dept_no.sh
[user1@centos ~]$ ../dept_no.sh
# 실행 권한 부여
[user1@centos ~]$ ls -l dept_no.sh
-rw-rw-r--. 1 user1 user1 226 Dec 5 17:05 dept_no.sh
[user1@centos ~]$ chmod u+x dept_no.sh
[user1@centos ~]$ ls -l dept_no.sh
-rwxrw-r--. 1 user1 user1 226 Dec 5 17:05 dept_no.sh
[user1@centos ~]$ ./dept_no.sh
***********************************
부서번호를 입력해주세요 : 20
***********************************
"Michael" 2004-02-17 "MK_MAN" 20
"Pat" 2005-08-17 "MK_REP" 20
'Data Base > Linux' 카테고리의 다른 글
| 231206 Linux 파라미터 변수, if문, for문, while문, eval (2) | 2023.12.06 |
|---|---|
| 231205 Linux shell ⓑ (1) | 2023.12.05 |
| 231205 Linux JAVA 설정 (1) | 2023.12.05 |
| 231204 Linux 사용자 계정 관리 (2) | 2023.12.04 |
| 231201 Linux 명령어2 (2) | 2023.12.01 |