■ DBWn(Database Writer)
1. data buffer cache 에 내용(dirty buffer)을 데이터 파일에 기록한다.
2. data buffer cache 에 있는 수정된 (dirty) buffer(commit, rollback의 경우) 를 데이터 파일로 기록한다.
3. dbwr 작동되는 시점
1) free buffer를 찾기 못했을 경우(free buffer wait event)
2) checkpoint event 발생할때(log swith, 디스크에 남겨) -> 'inactive' 상태
SQL> ! ps -ef | grep ora_dbw
oracle 28445 1 0 13:46 ? 00:00:02 ora_dbw0_ora11g

SQL> show parameter db_writer_processes

# SQL
SELECT *
FROM v$parameter WHERE name = 'db_writer_processes';
ALTER SYSTEM SET db_writer_processes = 2 SCOPE=SPFILE;
SELECT *
FROM v$parameter WHERE name = 'db_writer_processes';
SQL> ! ps -ef | grep dbw

SQL> show parameter db_writer_processes

■ LGWR(Log Writer)
1. Redo log buffer 에 있는 redo entry 를 redo log file 에 기록한다.
2. LGWR 작동시점
1) COMMIT 수행할 경우 : checkpoint
(1) SCN할당
(2) undo segment header commit 완료
(3) 수정된 행이 있는 block header
(4) LGWR 작동 -> current(group#1) write 작업
2) redo log buffer 가 1/3 찼을 경우
3) 1MB 이상의 redo entry 가 들어왔을 경우
4) 3초마다 (보험을 들어놓는다)
5) DBWr 가 기록하기 전에
# SCN(system commit number)
1. control file
2. block header
3. data file header block
# SQL
SELECT * FROM v$logfile;
# SQL
SELECT * FROM v$log;
SQL> ! ps -ef | grep lgwr
oracle 5443 1 0 Dec11 ? 00:00:00 ora_lgwr_ora11g

[oracle@oracle trace]$ pwd
/u01/app/oracle/diag/rdbms/ora11g/ora11g/trace

[oracle@oracle trace]$ tail -F alert_ora11g.log
■ CKPT(Checkpoint process)
1. checkpoint event 발생시점에 DBWR에 알려준다.
2. checkpoint 정보를 데이터 파일 헤더 갱신
3. checkpoint 정보를 컨트롤 파일 갱신
■ checkpoint
1. data buffer cache 있는 ditry buffer(block) (수정된 블록)을 정기적으로 디스크에 기록함으로 시스템이나 데이터베이스에 failure 가 발생한 경우 데이터가 손실되지 않도록 한다. (data write)
2. instance recovery 에 필요한 시간을 줄인다.
즉, 마지막 체크포인트 다음에 나오는 redo log file 에 redo entry 에 대해서 recovery 를 수행하면 된다.
3. 체크포인트 정보에는 체크포인트 시간, SCN, recovery 를 시작할 redo log file의 위치로 로그 정보를 가지고 있다.
4. 체크포인트가 발생하는 경우
1) shutdown normal | transactional | immediate 할 경우
SQL> shutdown immediate : 순서주의!
Database closed.
Database dismounted.
ORACLE instance shut down.

2) ALTER SYSTEM SET CHECKPOINT; (수동)
3) ALTER TABLESPACE users OFFLINE NORMAL; -> 사용하지 못하게 함
4) ALTER TABLESPACE users READ ONLY;
5) ALTER TABLESPACE users BEGIN BACKUP;
6) ALTER TABLESPACE users END BACKUP;
7) DROP TABLE 테이블명;
8) TRUNCATE TABLE 테이블명;
9) paralle query (select /*+ fill(e) paralle(e,2) */ from 테이블명 e;)
10) Log swith 발생시(ALTER SYSTEM SWITCH LOGFILE;)
11) fast_start_mttr_target 을 설정한 경우
SQL> show parameter fast_start_mttr_target

# log_checkpoints_to_alert = TRUE 설정을 하면 체크포인트 정보를 alert_SID.log 에 기록한다.
SQL> show parameter log_checkpoints_to_alert

SQL> ! ps -ef | grep ckpt
oracle 17083 1 0 01:32 ? 00:00:00 ora_ckpt_ora11g

■ SMON(System Monitor)
1. Instance recovery(Instance fail 시 인스턴스 복구하는 역할)
2. coalesces free space(디스크 조각모음)
3. 임시 블록 세그먼트들을 재사용할 수 있도록 하는 역할
SQL> ! ps -ef | grep smon
oracle 22463 22461 0 02:14 pts/2 00:00:00 grep smon

■ PMON(Process Monitor)
1. user process 가 실패할 경우 프로세스 recovery 수행
1) data buffer cache 정리
2) 사용하고 있는 리소스 해제
3) 트랜잭션에 대해서 자동 rollback
4) lock 해제
2. listener 에게 db 정보를 등록시키는 작업을 수행
SQL> ! ps -ef | grep pmon
oracle 17059 1 0 01:32 ? 00:00:00 ora_pmon_ora11g

■ Control file
1. 작은 binary file
2. database 이름, 식별자, 생성시간
3. data file, redo log file 이름 및 위치정보
4. 현재 online redo log file의 sequence 번호
5. checkpoint 정보, scn 정보
6. backup 정보
7. archivelog mode(운영중), noarchivelog mode(운영중X) 정보
8. control file 은 다중화 하자
# SQL
SELECT * FROM v$database;
# SQL
SELECT dbid, name, checkpoint_change#, current_scn
FROM v$database;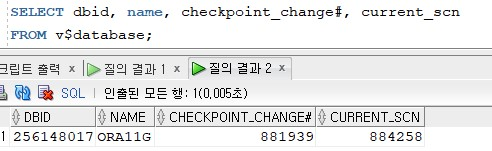
# SQL
SELECT dbid, name, checkpoint_change#, current_scn FROM v$database; --#881939
SELECT name, checkpoint_change# FROM v$database;
SELECT * FROM v$log;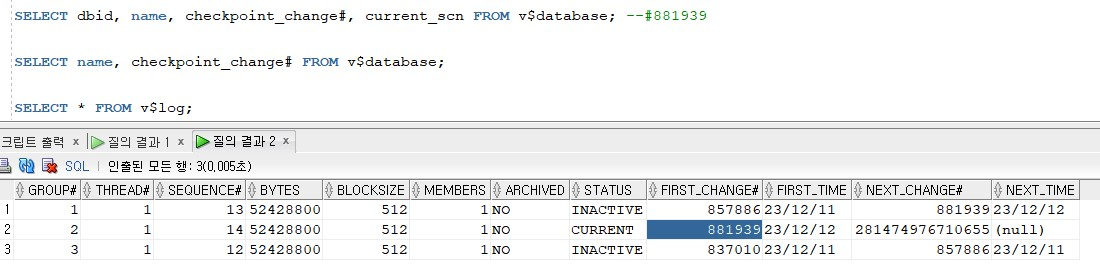
SQL> show parameter control_files
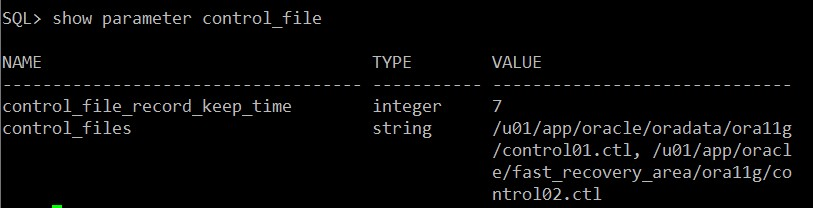
[oracle@oracle dbs]$ cat initora11g.ora
...
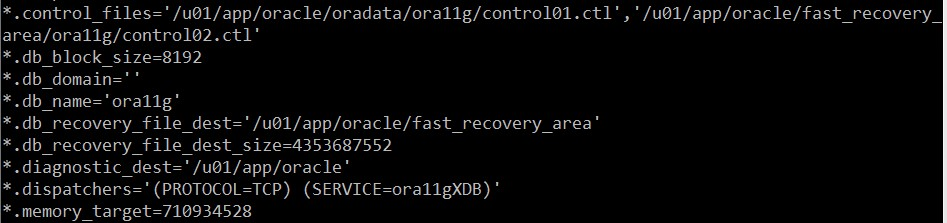
*.control_files='/u01/app/oracle/oradata/ora11g/control01.ctl','/u01/app/oracle/fast_recovery_area/ora11g/control02.ctl' -> file 위치 및 control 복사본 이중화 확인
...
# SQL
SELECT *
FROM v$parameter
WHERE name = 'control_files';
[oracle@oracle ~]$ mkdir backup
[oracle@oracle ~]$ ls
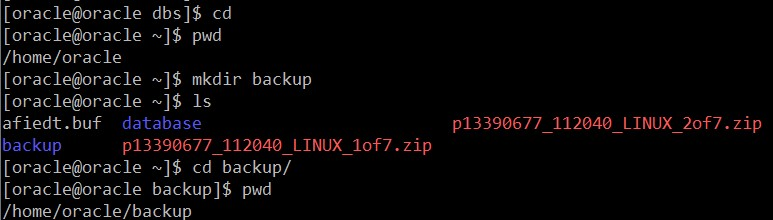
[oracle@oracle ~]$ cd backup/
[oracle@oracle backup]$ pwd
/home/oracle/backup
□ control file 다중화
초기 파라미터 파일이 서버 파라미터 파일로 운영하고 있다.
SPFILE
SQL> show parameter spfile

1. 기존 파일을 새로운 파일로 위치 및 내용 복사하기
ALTER SYSTEM SET control_files =
'/u01/app/oracle/oradata/ora11g/control01.ctl', -- 기존파일위치
'/u01/app/oracle/fast_recovery_area/ora11g/control02.ctl',
'/home/oracle/backup/control03.ctl' SCOPE=SPFILE; -- 새로운 위치
★ 2. DB 를 정상적인 종료
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> !
3. 기존 control file을 다른 위치에 복사(cp)
[oracle@oracle ~]$ cp -v /u01/app/oracle/oradata/ora11g/control01.ctl /home/oracle/backup/control03.ctl
‘/u01/app/oracle/oradata/ora11g/control01.ctl’ -> ‘/home/oracle/backup/control03.ctl’

# 확인방법
[oracle@oracle ~]$ ls -l /home/oracle/backup/

4. 오라클로 접속한 후 DB 시작
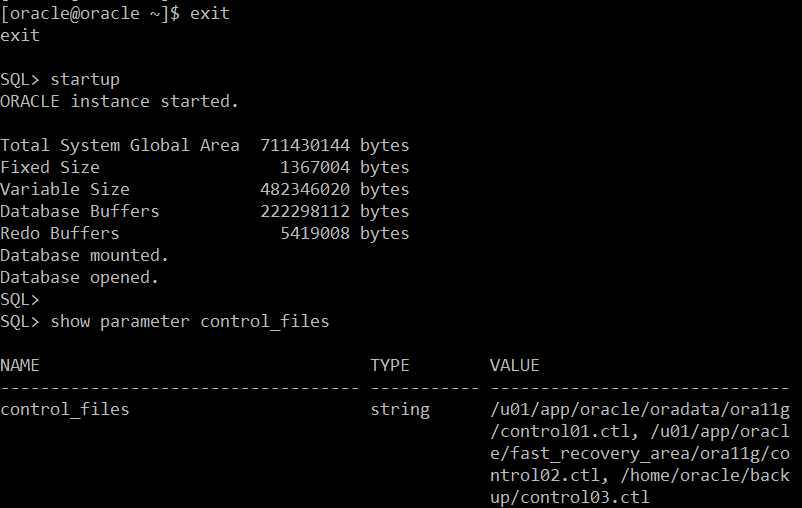
[oracle@oracle ~]$ exit
exit
SQL> startup
ORACLE instance started.
Total System Global Area 711430144 bytes
Fixed Size 1367004 bytes
Variable Size 482346020 bytes
Database Buffers 222298112 bytes
Redo Buffers 5419008 bytes
Database mounted.
Database opened.
SQL> show parameter control_files
□ control file 이중화
1. 원상복구 작업, 원본 파일만 두고 SCOPE=SPFILE 설정해주자
ALTER SYSTEM SET control_files =
'/u01/app/oracle/oradata/ora11g/control01.ctl',
'/u01/app/oracle/fast_recovery_area/ora11g/control02.ctl' SCOPE=SPFILE;
★ 2. DB 를 정상적인 종료
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> !
SQL> startup

SQL> show parameter control_files
'Data Base > Linux' 카테고리의 다른 글
| 231213 Linux_DB, OS DB (0) | 2023.12.13 |
|---|---|
| 231213 Linux_Redo log file (0) | 2023.12.13 |
| 231212 Linux_ASMM, PGA, SGA, AMM (0) | 2023.12.12 |
| 231211 Linux_SAG, Database Buffer Cache, Data Buffer Cache, shared pool, Large pool, Java pool, Stream pool, REDO LOG BUFFER (1) | 2023.12.11 |
| 231211 Linux_초기 파라미터 파일, spfile, pfile (2) | 2023.12.11 |