# 운영 중에 장애발생 : '/u01/app/oracle/oradata/ora11g/system01.dbf'
#) 현재 SCN 확인
select current_scn from v$database;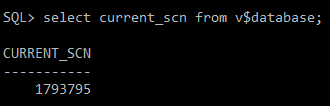
#) data file의 checkpoint_SCN 확인
select name, checkpoint_change# from v$datafile;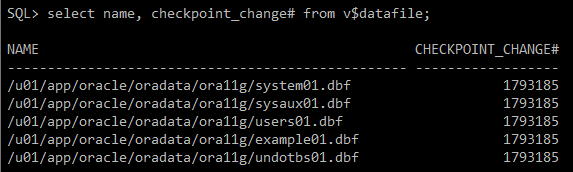
#) redo log 정보 확인
select STATUS, SEQUENCE#, FIRST_CHANGE#, NEXT_CHANGE# from v$log;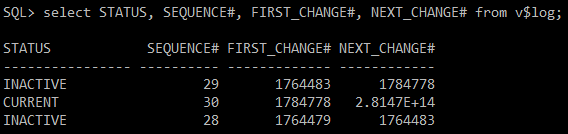
# 장애 유발 #
#) system01.dbf 삭제
! rm /u01/app/oracle/oradata/ora11g/system01.dbf
◎ full checkpoint
=> DB가 정지 되거나 백업 작업을 수행할 때 발생하며, 모든 변경 내용을 디스크에 안전하게 저장함으로써 데이터의 일관성과 내구성을 유지함.
- 모든 변경 내용이 디스크에 기록되어 영구적으로 저장되도록 하는 작업
1) dirty buffer의 모든 내용을 디스크에 기록
2) redo log file에 기록
3) 모든 데이터 파일의 checkpoint 정보 갱신
#) 강제 스위치 발생
alter system checkpoint;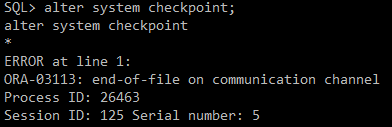
=> DB 불안전하게 내려감
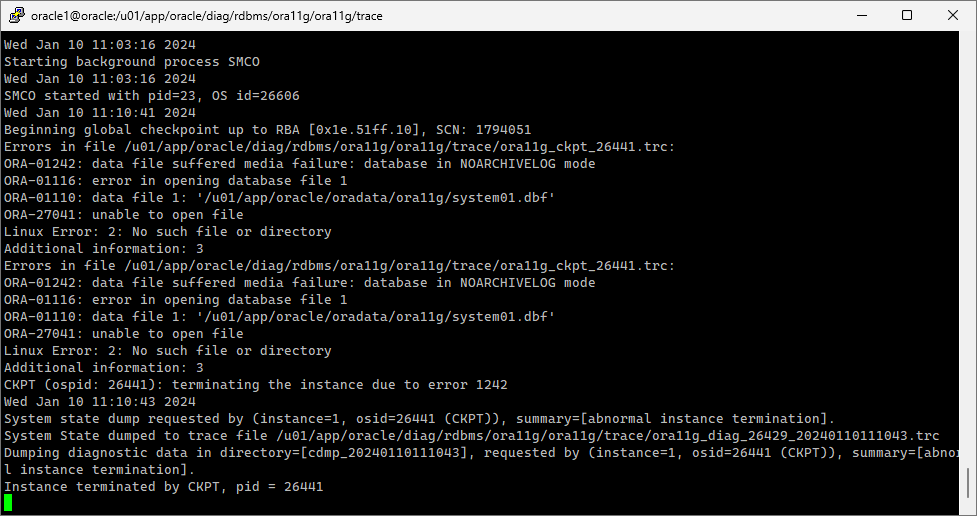
#) instance 상태 확인
=> 상태 확인 안됨.
alter system checkpoint;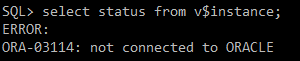
#) 접속 끊어짐, session 잃어버림
startup
#) 재접속
conn / as sysdba
#) DB 올리기
=> mount단계까지만 올라옴
startup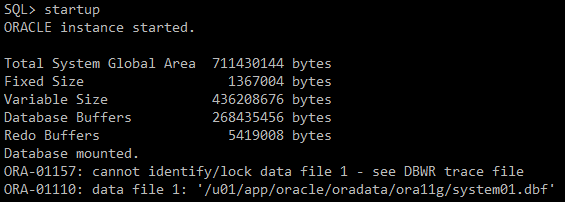
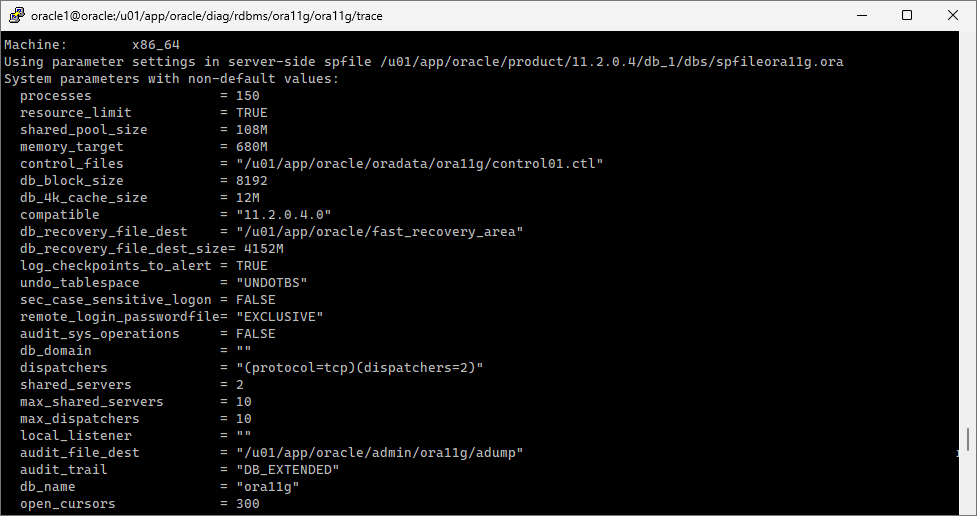
#) instance 상태 확인
select status from v$instance;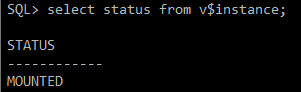
#) system01.dbf 상태는 system 으로 확인되나, offline 모드/online 모드 변경 작업 불가
select name, status from v$datafile;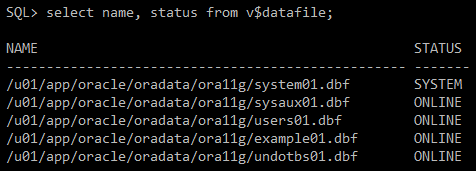
# 해결 방법 #
#) 백업 restore 작업해야 한다.
SQL> !
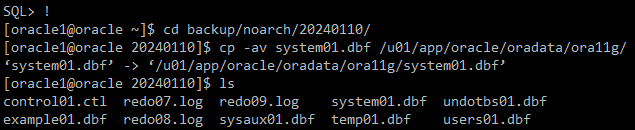
[oracle1@oracle ~]$ cd backup/noarch/20240110/
=> 가장 최근까지의 백업파일본으로 copy
[oracle1@oracle 20240110]$ cp -av system01.dbf /u01/app/oracle/oradata/ora11g/
‘system01.dbf’ -> ‘/u01/app/oracle/oradata/ora11g/system01.dbf’
[oracle1@oracle 20240110]$ ls
control01.ctl redo07.log redo09.log system01.dbf undotbs01.dbf
example01.dbf redo08.log sysaux01.dbf temp01.dbf users01.dbf
=> system01.dbf 확인해보기
#) 오라클로 접속
=> system tablespace 복구
- 마지막 백업 시점 이후 변경 이력정보를 redo log file 에서 찾아서 복구 작업 진행한다.
- 백업 시점의 마지막 체크포인트(SCN)
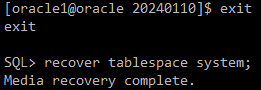
[oracle1@oracle 20240110]$ exit
recover tablespace system;=> redo 에 정보가 있을 경우

#) DB open 단계로 올리기
alter database open;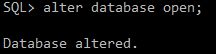
#) redo log 확인
- 이전 redo 값으로 확인
select STATUS, SEQUENCE#, FIRST_CHANGE#, NEXT_CHANGE# from v$log;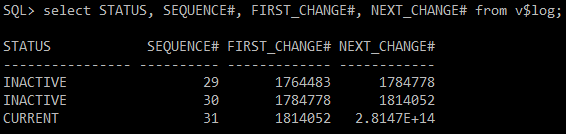
select name, status from v$datafile;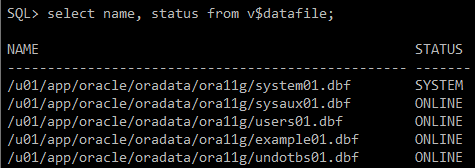
#) SCN 번호 일치하는지 확인
select name, checkpoint_change# from v$datafile;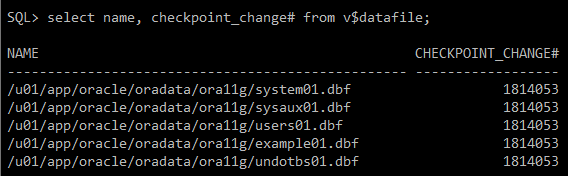
#) 복구 완료
'Backup > Noarchive Log Mode' 카테고리의 다른 글
| SYSTEM TABLESPACE 속한 데이터 파일이 손상되었을 경우(backup 이후에 REDO 가 없을 경우) (0) | 2024.01.11 |
|---|---|
| 모든 data file, redo log file, control file이 있는 디스크 손상되었을 경우 (0) | 2024.01.10 |
| Noarchive Log Mode backup 기본 (1) | 2024.01.09 |
| BackUp 받지 않는 Tablespace 손상되었을 경우 ⓒ (0) | 2024.01.09 |
| BackUp 받지 않는 Tablespace 손상되었을 경우 ⓑ (0) | 2024.01.09 |