목표: redo에 대한 복구작업을 수행할 수 있다.
archive log file이 생성된 후 inactive log file이 삭제됨 이후 db close된 상태이다.
1. 리두 그룹, 시퀀스, 맴버, 사이즈, 아카이브모드, 상태 조회
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;
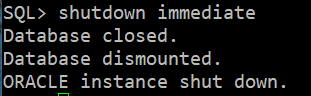
2. DB 정상적 다운
SQL> shutdown immediate
3. 장애유발 (inactive상태의 redo file을 지울 것 ) ★
! rm /u01/app/oracle/oradata/ora11g/redo02.log
! ls /u01/app/oracle/oradata/ora11g/redo02.log
--> ls: cannot access /u01/app/oracle/oradata/ora11g/redo01.log: No such file or directory

1) startup
SQL> startup
=> channel 끊김의 오류발생

2) instance체크 및 재접속
select status from v$instance;
SQL> conn / as sysdba

--> redo log file이 없으니 DB가 내려앉아버림 ★★
--> 마운트까지도 못올렸다
[oracle@oracle trace]$ cd $ORACLE_BASE/ diag/rdbms/ora11g/ora11g/trace/
[oracle@oracle trace]$ tail -F alert_ora11g.log
--> 확인 가능

4. 해결방법
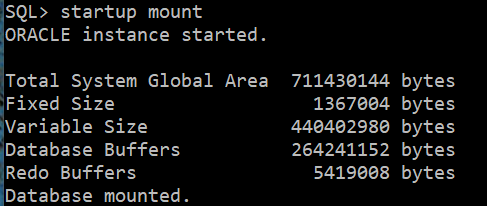
1) startup mount
SQL> startup mount
2) 컨트롤파일이 들고있는 redo정보
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;
--> 장애유발된 그룹번호 확인 : 2번 그룹
3) 그룹삭제
alter database drop logfile group 2;
4) 컨트롤 파일이 갖고 있는 redo정보 조회
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;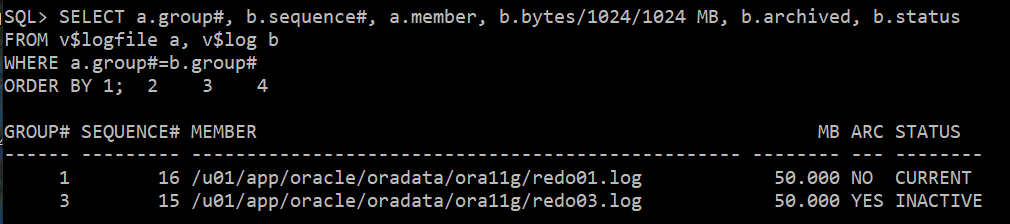
--> 2번그룹 삭제
5) DB 오픈
alter database open;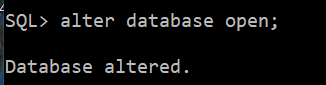
6) 그룹추가 ★
alter database add logfile group 2 '/u01/app/oracle/oradata/ora11g/redo02.log' size 50m;
#) 그룹 추가 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;
# 시나리오13
DB가 열린상태에서 current한 그룹이 아닌 redo log file이 삭제될 때 어떤일이 발생하고 어떻게 복구할까
POINT: inactive상태인 그룹이 삭제되고 그 그룹을 인지를 못하고 로그스위치가 발생하면 아카이브파일에 갭이 생긴다. 이때, Clear작업 해야한다 (리두그룹을 삭제하고 자동생성)
tip) 클리어명령어: alter database clear unarchived logfile group 2;
1. REDO 조회
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;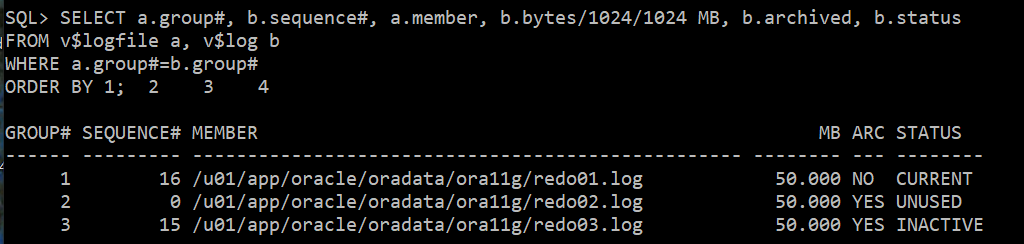
--> 현재 Current한 그룹체크 : 1번
2. 로그 스위치 강제 발생
alter system switch logfile;
3. REDO 조회
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;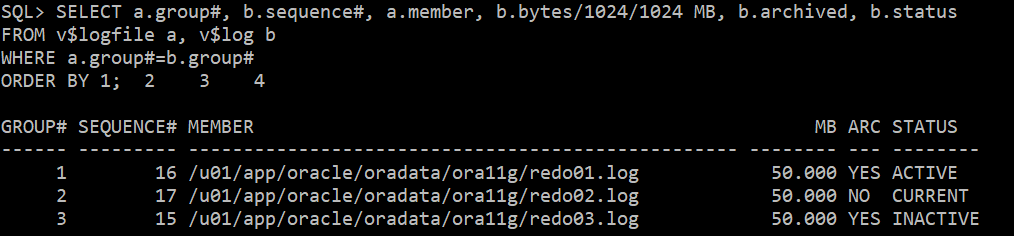
--> 현재 Current한 그룹체크 : 17번
--> 만약 current, active, active상태라면 => alter system checkpoint; 더티버퍼가 다 내려가기 때문
4. 아카이브 파일 떨어진 것 조회
select * from v$archived_log;
select sequence#, stamp, name, dest_id, thread#, activation#
from v$archived_log;
--> 잘 떨어짐
SQL> ! ls /home/oracle/arch1
arch_1_14_1156667649.arc arch_1_15_1156667649.arc arch_1_16_1156667649.arc
14 1158911105 /home/oracle/arch1/arch_1_14_1156667649.arc 1 1 257926591
15 1158912961 /home/oracle/arch1/arch_1_15_1156667649.arc 1 1 257926591
16 1158914814 /home/oracle/arch1/arch_1_16_1156667649.arc 1 1 257926591
5. 장애유발 ★★
1) db open상태에서 inactive상태인 리두그룹 삭제
GROUP# SEQUENCE# MEMBER MB ARC STATUS
3 15 /u01/app/oracle/oradata/ora11g/redo03.log 50.000 YES INACTIVE
SQL> ! ls /u01/app/oracle/oradata/ora11g/redo03.log
/u01/app/oracle/oradata/ora11g/redo02.log

SQL> ! rm /u01/app/oracle/oradata/ora11g/redo03.log
SQL> ! ls /u01/app/oracle/oradata/ora11g/redo03.log
ls: cannot access /u01/app/oracle/oradata/ora11g/redo03.log: No such file or directory

2) 로그스위치 시켜보기
SQL> alter system switch logfile;
System altered.
--> 있어야할 redo log file이 없으면 행상태로 바뀜 즉, 중단
--> 해지하려면, ctrl+c
SQL> /
^Calter system switch logfile
*
ERROR at line 1:
ORA-01013: user requested cancel of current operation

--> [oracle@oracle trace]$ tail -F alert_ora11g.log

3) redo정보 조회 및 archive조회
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;
--> current한 그룹: 2번 seq#:20
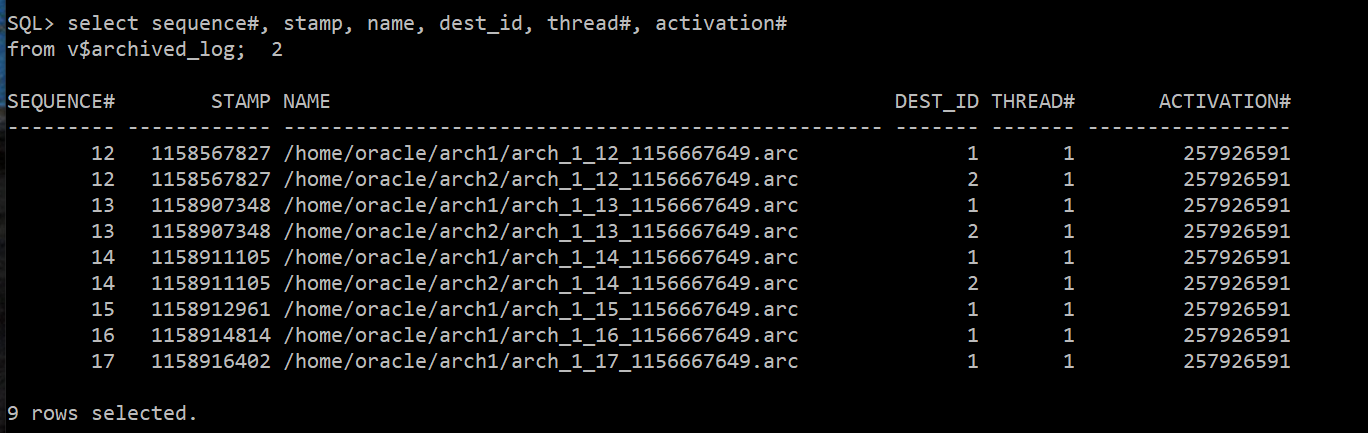
select * from v$archived_log;
select sequence#, stamp, name, dest_id, thread#, activation#
from v$archived_log;
--> 아카이브 파일에 갭이 생김
--> why? 현재 current한 redo는 seq#:7인데 아카이브는 6까지 쌓여야하는데 4까지 쌓임
★ --> clear작업 수행해야함 ★
4) Clear작업 수행 ★★★
SQL> ! ls /u01/app/oracle/oradata/ora11g/redo03.log
ls: cannot access /u01/app/oracle/oradata/ora11g/redo03.log: No such file or directory

alter database clear unarchived logfile group 3;
--> Database altered.
--> 해석) 3번 그룹 로그그룹을 삭제하고 재생성할건데 아카이브는 받지마!
(--> 생각외로 오래걸릴 수 있다!)

SQL> ! ls /u01/app/oracle/oradata/ora11g/redo03.log
/u01/app/oracle/oradata/ora11g/redo03.log
--> File을 재생성 해줬음 ★

5) redo에 재생성한 그룹조회
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;

select * from v$archived_log;
select sequence#, stamp, name, dest_id, thread#, activation#
from v$archived_log;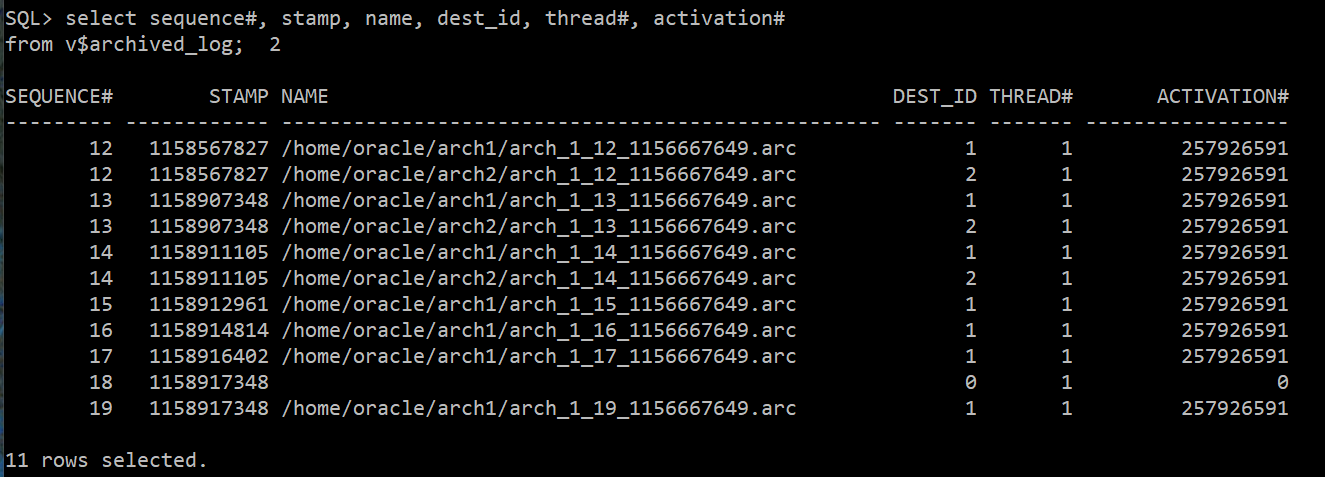
--> 아카이브 파일에 갭이 생겨서 이순간 cold, hot backup을 받아야한다. ★
6) cold backup recovery
[oracle@oracle cold_20240117]$ cp -av *.dbf /u01/app/oracle/oradata/ora11g/
[oracle@oracle cold_20240117]$ cp -av *.ctl /u01/app/oracle/oradata/ora11g/
[oracle@oracle cold_20240117]$ cp -av *.log /u01/app/oracle/oradata/ora11g/
[oracle@oracle cold_20240117]$ ls
control01.ctl example01.dbf initora11g_20240117.ora redo01.log redo02.log redo03.log sysaux01.dbf system01.dbf temp01.dbf undotbs01.dbf users01.dbf
SQL> startup
ORACLE instance started.
Total System Global Area 711430144 bytes
Fixed Size 1367004 bytes
Variable Size 448791588 bytes
Database Buffers 255852544 bytes
Redo Buffers 5419008 bytes
Database mounted.
Database opened.
--> 우리는 dest를 2개에서 1개로 수정햇는데 백업controlfile은 2개로 저장되어있던 시점의 파일임
--> startup을하면 제대로 올라갈까?
--> 올라가긴함
--> why? 초기파라미터 정보를 보면서 write되기때문
7) 이전 archive지우기
! ls /home/oracle/arch1
! rm /home/oracle/arch1/*.*
! ls /home/oracle/arch1
8) 현재 리두상태 조회
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;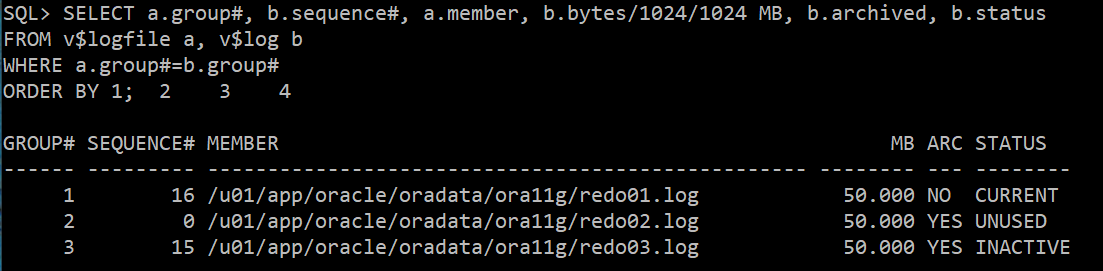
9) 아카이빙 한번 받기
alter system switch logfile; x2 (unused 상태 없앨라고 그냥 2번하는거임)

조회
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status
FROM v$logfile a, v$log b
WHERE a.group#=b.group#
ORDER BY 1;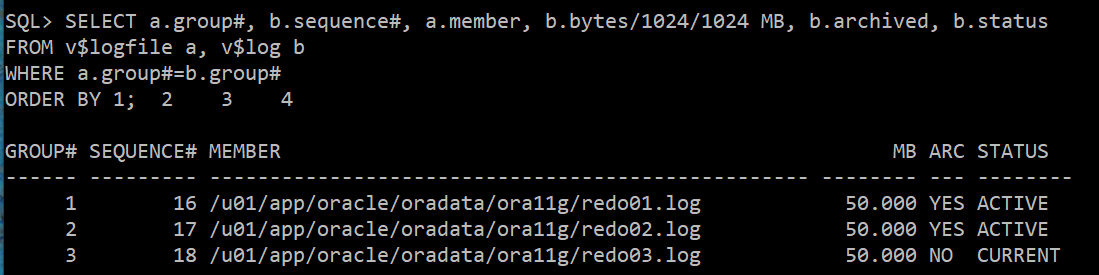
SQL> ! ls /home/oracle/arch1

'Backup > Archive Log Mode' 카테고리의 다른 글
| current한 redo group이 삭제된 후 복구 작업 (0) | 2024.01.22 |
|---|---|
| 일관성 있는 백업, 일관성 없는 백업 / 아카이브 단일화 (1) | 2024.01.22 |
| Log Miner (로그 마이너) (0) | 2024.01.22 |
| 복제 DB, Clone (0) | 2024.01.22 |
| 운영 중인 DB 에서 tablespace 삭제했을 경우 (0) | 2024.01.19 |