■ cancel based recovery
#) redo log 정보 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status, b.first_time, b.first_change#, b.next_change#
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;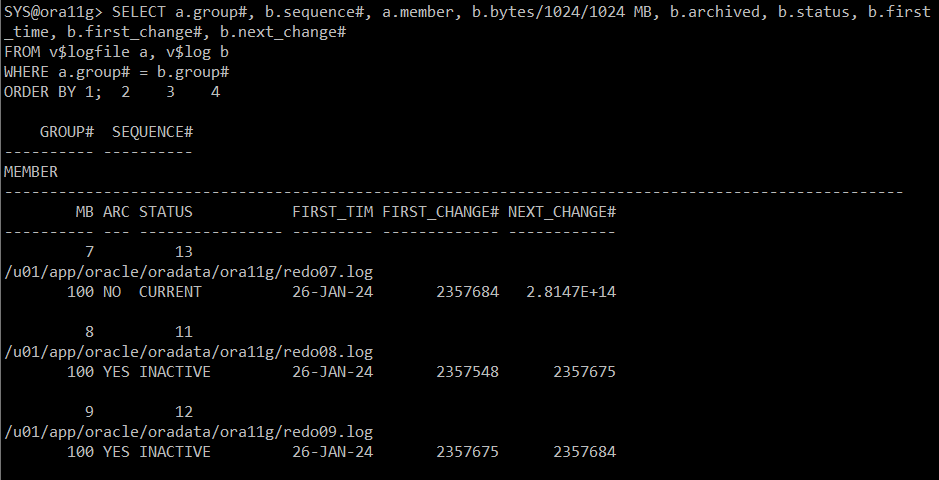
<rman session>
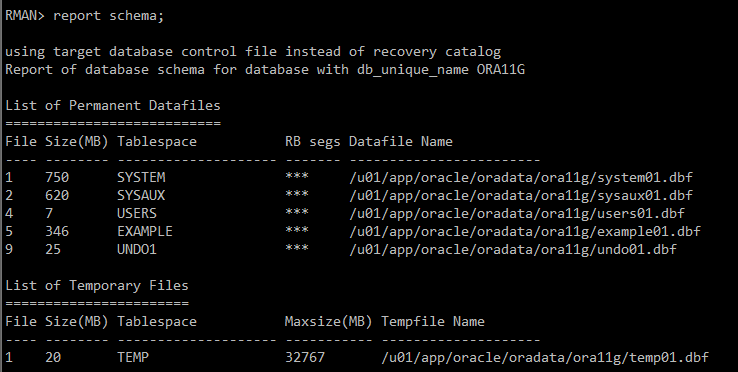
RMAN> report schema;
<ora11g session>
#) 디렉터리 생성
SYS@ora11g> !
[oracle1@oracle ~]$ cd backup/
[oracle1@oracle backup]$ ls
[oracle1@oracle backup]$ mkdir rman
[oracle1@oracle backup]$ ls
[oracle1@oracle backup]$ cd rman/
[oracle1@oracle rman]$ pwd
/home/oracle1/backup/rman

<rman session>
RMAN> show all;
=> 저장할 위치 확인
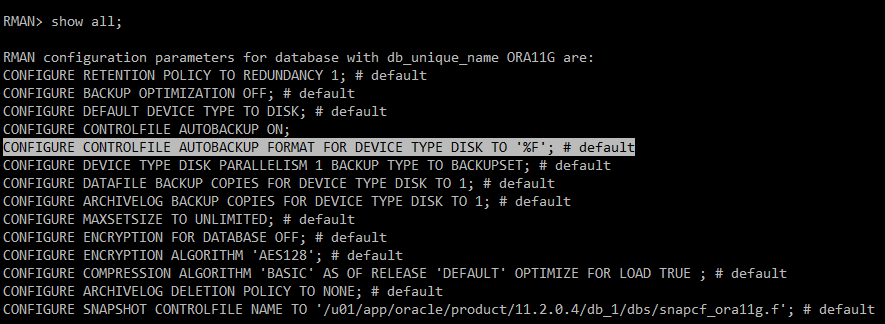
#) 위치 변경
RMAN> CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/home/oracle1/backup/rman/%F';

#) 저장할 위치 변경 후 설정 확인
RMAN> show all;

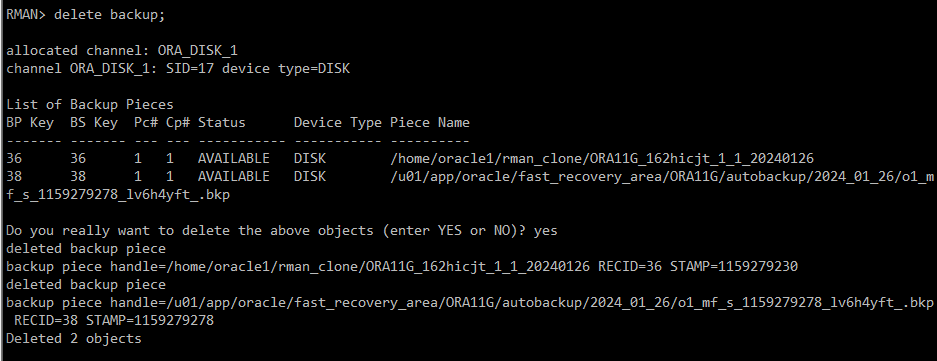
#) 기존에 있던 백업 정보 삭제
RMAN> delete backup;
#) 백업 확인
RMAN> list backup;

#) 백업 받기
RMAN> backup as compressed backupset format '/home/oracle1/backup/rman/%d_%U_%T' database;

#) 백업 확인
RMAN> list backup;
#1) data file 저장된 위치 확인

#2) control file 저장된 위치 확인

<ora11g session>
#) redo 정보 확인
=> scn 번호 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status, b.first_time, b.first_change#, b.next_change#
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;
#) 테이블 생성 후 확인
=> SEQUENCE# : 13
create table hr.emp_arch as select * from hr.employees;
select count(*) from hr.emp_arch;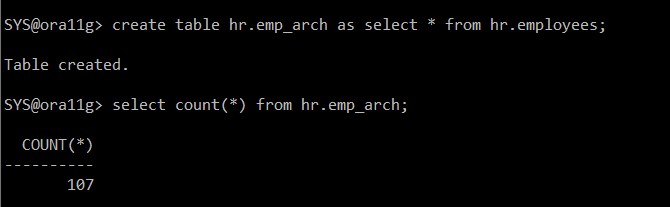
#) 로그 스위치 발생*3
alter system switch logfile;
#) 아카이브 정보 확인
! ls /home/oracle1/arch1

#) 테이블 생성
=> SEQUENCE# : 16
create table hr.dept_arch as select * from hr.departments;
select count(*) from hr.dept_arch;
#) 로그 스위치 발생
alter system switch logfile;
#) redo log 정보 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status, b.first_time, b.first_change#, b.next_change#
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;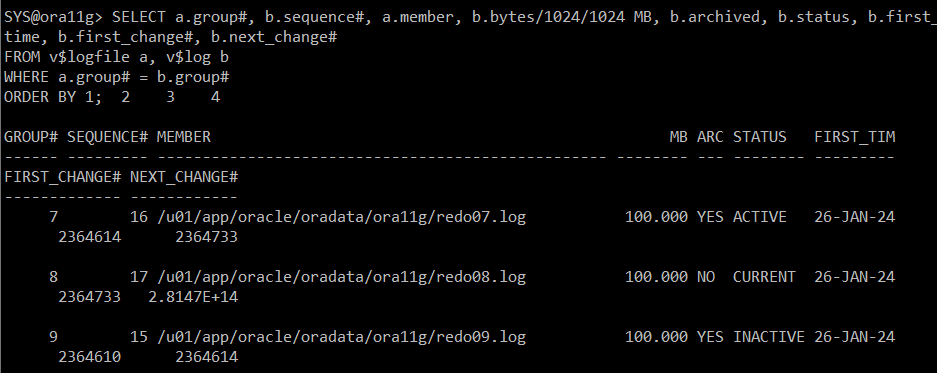
#) data file 확인
SELECT a.file#, a.name AS file_name, b.name AS tbs_name, a.status, a.checkpoint_change#
FROM v$datafile a, v$tablespace b
WHERE a.ts# = b.ts#;
#) archive log 확인
select sequence#, name from v$archived_log where name is not null;
#) 장애 유발
=> tablespace, 아카이브 파일 삭제
! rm /u01/app/oracle/oradata/ora11g/users01.dbf
! rm /home/oracle1/arch1/arch_1_15_1159199033.arc
#) 정상적인 DB 내리기
shutdown immediate
=> 내려가질 않는다. 그래서 비정상적인 종료 시
shutdown abort
#) DB 올리기
=> 오류 발생, data file인 users01.dbf 없다고 확인
startup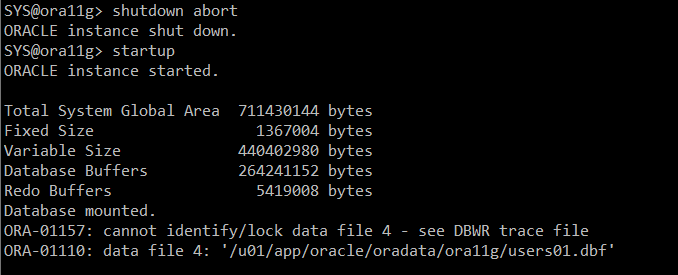
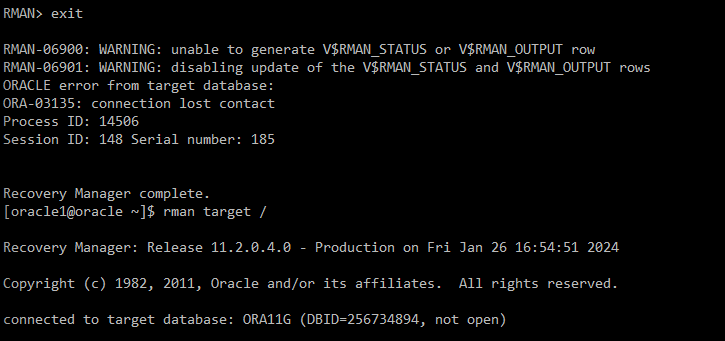
<rman 재접속>
RMAN> exit
[oracle1@oracle ~]$ rman target /
#) 장애 확인
RMAN> list failure;

RMAN> list failure 82 detail;
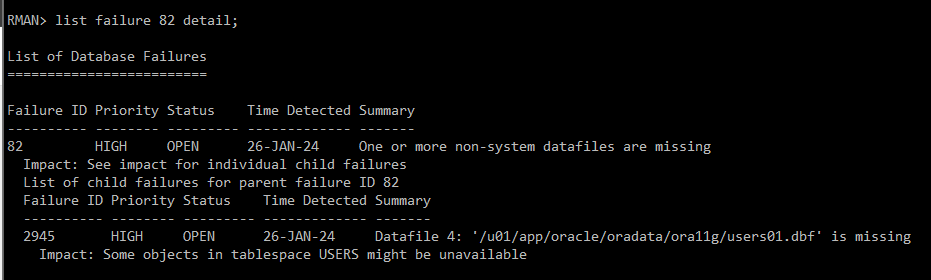
#) 삭제한 tablespace 복구 하기
RMAN> restore tablespace users;
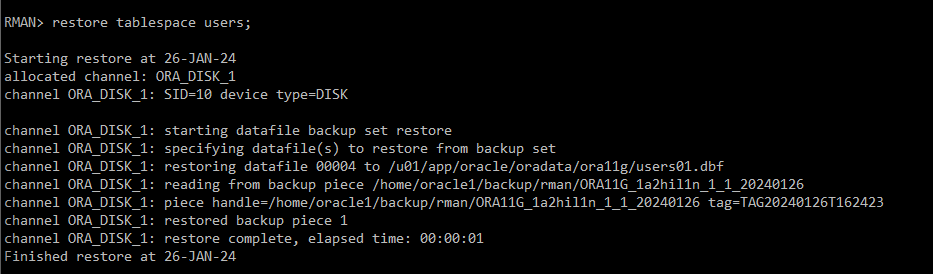
#) 삭제한 tablespace recover 시도!
=> 완전복구 실패 /
=> seq# 15 SCN: 2364610 복구 가능!
RMAN> recover tablespace users;

#) 비정상적인 종료 DB 후 nomount 단계까지 올리기
=> control file 올리기 전까지 올려야 한다. 그래야 scn 번호도 맞출 수 있다.
=> 불안전한 복구 해야 한다!
RMAN> shutdown abort
RMAN> startup nomount

#) control file 저장된 위치 확인해서 복구 하기
=> control file 저장된 위치 : /home/oracle1/backup/rman/c-256734894-20240126-02
RMAN> restore controlfile from '/home/oracle1/backup/rman/c-256734894-20240126-02';
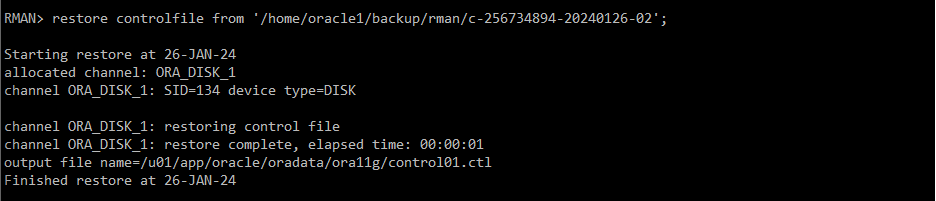
#) mount단계까지 DB 올리기
RMAN> alter database mount;

#) 전체 database 복구하기
RMAN> restore database;

#) recover 하기
=> scn번호 이전까지 복구 한다는 의미이다.
RMAN> recover database until scn 2364610;

#) DB를 resetlogs 로 오픈하기
RMAN> alter database open resetlogs;

<ora11g session>
#) 재접속 후 redo log 정보 확인
conn / as sysdba
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status, b.first_time, b.first_change#, b.next_change#
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;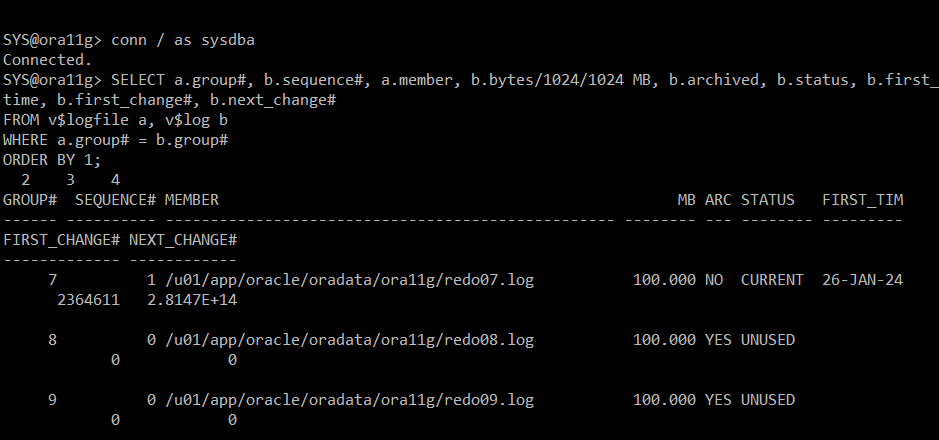
#) data file 확인
SELECT a.file#, a.name AS file_name, b.name AS tbs_name, a.status, a.checkpoint_change#
FROM v$datafile a, v$tablespace b
WHERE a.ts# = b.ts#;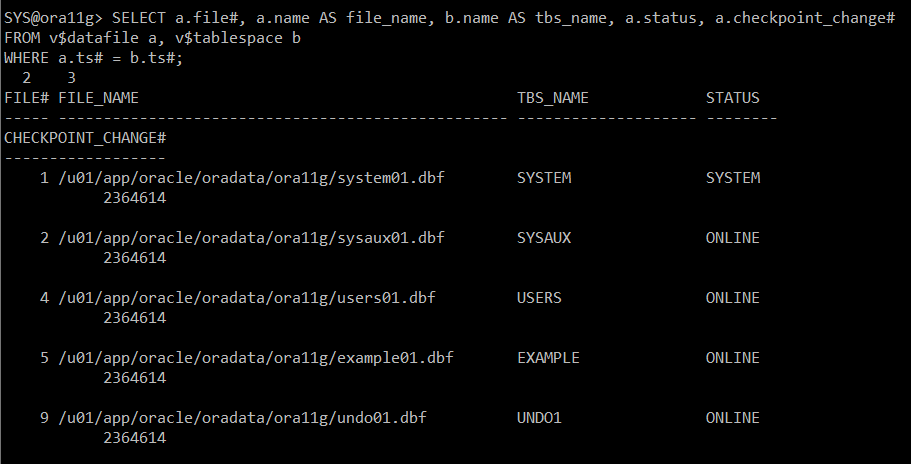
#) 장애 나기 전의 테이블 확인
=> seq#:13 은 복구 / seq#: 16 은 복구X
select count(*) from hr.emp_arch;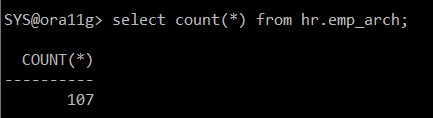
select count(*) from hr.dept_arch;
'Backup > RMAN' 카테고리의 다른 글
| control file이 장애 났을 경우 ⓑ (0) | 2024.01.29 |
|---|---|
| control file이 장애 났을 경우 ⓐ (0) | 2024.01.29 |
| clone DB 이용해서 삭제된 table ora11g DB import 하기 (1) | 2024.01.26 |
| clone DB 생성 후 운영 중인 table 삭제했을 경우 (1) | 2024.01.26 |
| 백업 받은 tablespace 운영 중에 삭제했을 경우 (1) | 2024.01.25 |