#) shared pool 을 비워주는 명령*2번
alter system flush shared_pool;
SELECT sql_id, sql_text, parse_calls, loads, executions
FROM v$sql
WHERE sql_text LIKE '%hr.employees%'
AND sql_text NOT LIKE '%v$sql%';
#) 샘플 테이블 생성
create table hr.emp as select * from hr.employees;
alter system flush shared_pool;
#) 확인
select last_name, salary from hr.emp where employee_id = 100;
#) 조회했는지 확인
SELECT sql_id, sql_text, parse_calls, loads, executions
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';
#) invalidations = 무효화 유무 확인
SELECT sql_id, sql_text, parse_calls, loads, executions, invalidations
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';
#) 실행계획 정보 확인
=> 통계정보(모집단)가 있어야 실행계획을 생성이 가능하다.
select * from table(dbms_xplan.display_cursor('8qhp0dmv9q94d'));=> dynamic sampling used for this statement (level=2) => 동적인 표본추출(dynamic sampling)
#) 표본추출
select num_rows, blocks, avg_row_len from dba_tables where owner = 'HR' and table_name = 'EMP';NUM_ROWS BLOCKS AVG_ROW_LEN
(row의 수) (block 수) (한 행의 byte 값)
#) 통계수집을 하고 싶다면?
SELECT sql_id, sql_text, parse_calls, loads, executions, invalidations
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';
# 통계 수집
execute dbms_stats.gather_table_stats('hr','emp', no_invalidate=>false)
#) 통계수집 확인
select num_rows, blocks, avg_row_len from dba_tables where owner = 'HR' and table_name = 'EMP';
#) 실행계획의 무효화 확인
SELECT sql_id, sql_text, parse_calls, loads, executions, invalidations
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';
#) hr 계정에서 select
select last_name, salary from hr.emp where employee_id = 100;
LAST_NAME SALARY
------------------------- ----------
King 24000
#) 실행계획을 loads 증가되었는지 확인
SELECT sql_id, sql_text, parse_calls, loads, executions, invalidations
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';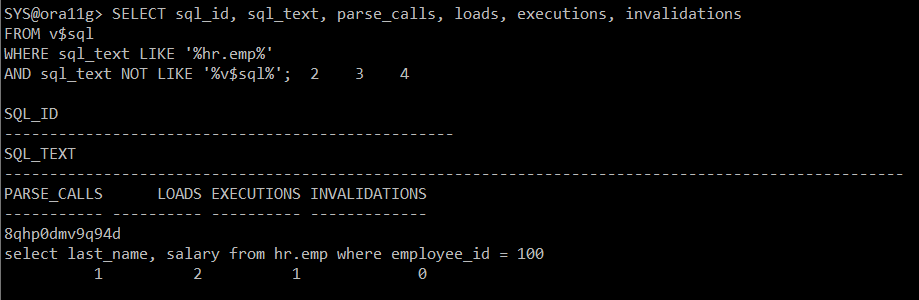
#) 실행계획 확인
=> 통계수집했기 때문에
select * from table(dbms_xplan.display_cursor('8qhp0dmv9q94d'));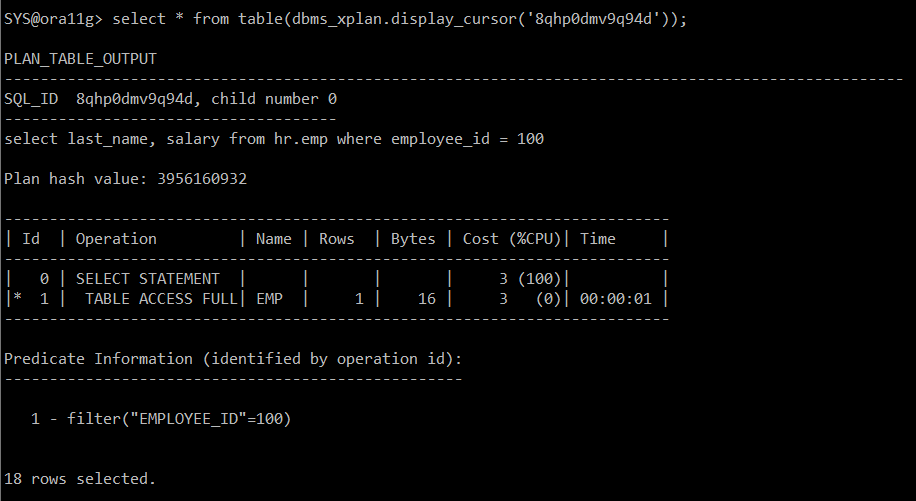
#) index 생성
=> uniqe index 생성
create unique index hr.emp_idx on hr.emp(employee_id);
#) primary key 추가로 생성하기
alter table hr.emp add constraint emp_id_pk primary key(employee_id);
=> 원래 문법(제약 조건을 삭제 했다가 다시 추가 생성해본다!)
alter table hr.emp add constraint emp_id_pk primary key(employee_id) using index hr.emp_idx;
#) 제약조건 확인
select * from dba_constraints where table_name ='EMP' and owner = 'HR';
#) 제약조건 변경 후 무효화 확인
SELECT sql_id, sql_text, parse_calls, loads, executions, invalidations
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';
#) HR 계정에서 select문
select last_name, salary from hr.emp where employee_id = 100;
#) 실행계획 확인
=> loads 수 변화
SELECT sql_id, sql_text, parse_calls, loads, executions, invalidations
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';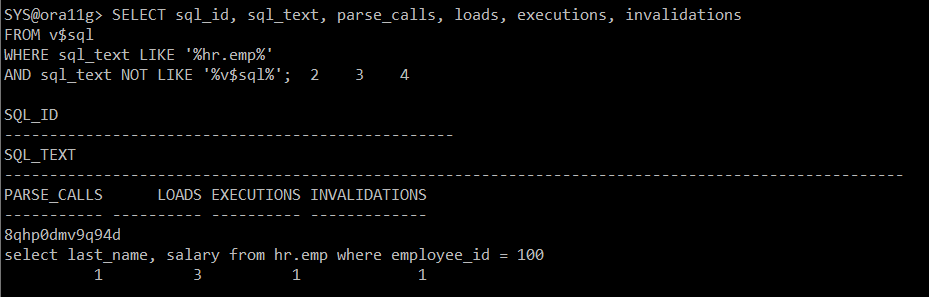
#) 컬럼들의 정보 확인
desc hr.emp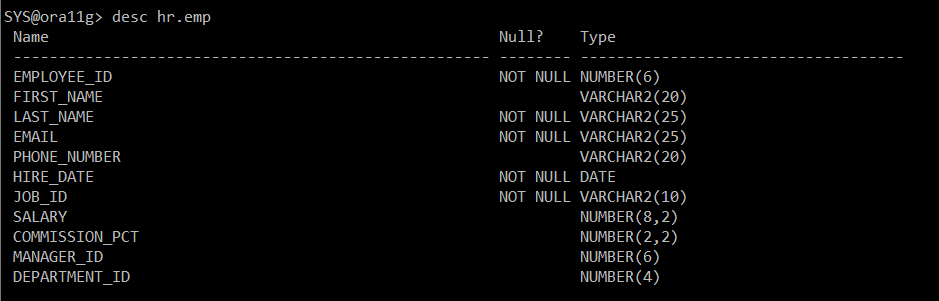
#) type 변경
LAST_NAME VARCHAR2(25) -> 30자리로
alter table hr.emp modify last_name varchar2(30);
#) 다시 확인해보기
desc hr.emp
#) 무효화의 발생했는지 확인
SELECT sql_id, sql_text, parse_calls, loads, executions, invalidations
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';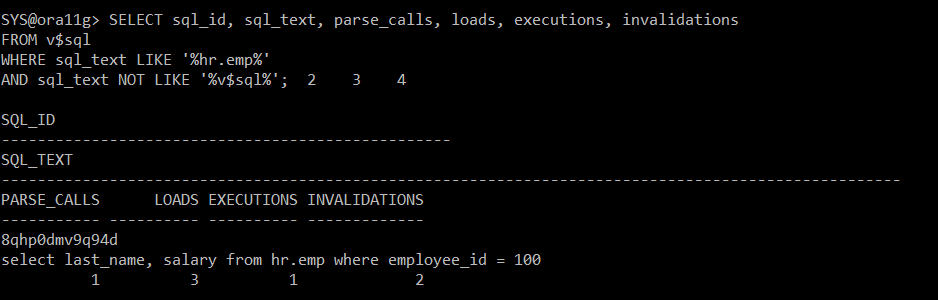
#) HR 게정 에서의 select 문
select last_name, salary from hr.emp where employee_id = 100;
#) loads 수 변경
SELECT sql_id, sql_text, parse_calls, loads, executions, invalidations
FROM v$sql
WHERE sql_text LIKE '%hr.emp%'
AND sql_text NOT LIKE '%v$sql%';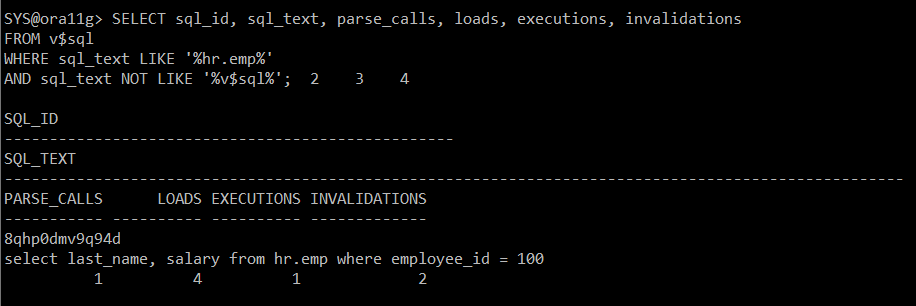
◎ invalidations(무효화) 발생하는 경우
1) 통계수집
2) 테이블 구조 변경(컬럼 타입 변경 등)
3) 제약조건 추가(index 생성, primary key 추가)
'Data Base > SQL 튜닝' 카테고리의 다른 글
| Library Cache Pin _ procedure 생성 후 library cache pin 확인 (0) | 2024.02.05 |
|---|---|
| Library Cache Lock_table 생성, 대량의 Data (1) | 2024.02.05 |
| Library Cache Lock _ 같은 session에서 procedure 실행 후 wait event 확인 (0) | 2024.02.05 |
| shared pool _ select문의 실행 계획 (1) | 2024.02.03 |
| SAG(System Global Area) shared pool(공유 메모리), SELECT문 처리과정 (0) | 2024.02.03 |