■ 집합 연산자
UNION(합집합), UNION ALL(합집합), INTERSECT(교집합), MINUS(차집합)
a. SELECT 절의 컬럼의 갯수가 일치해야 한다.
b. 첫 번째 SELECT 절의 대응되는 두 번째 SELECT 절 컬럼의 데이터 타입이 일치해야 한다.
c. UNION, INTERSECT, MINUS 연산자는 중복을 제거한다.(먼저, 내부적으로 정렬이 발생한다.)
d. UNION ALL 은 중복되는 데이터도 포함하기 때문에 내부적으로 정렬이 발생하지 않는다.
e. 집합 연산자에서 ORDER BY 절은 제일 마지막에 작성해야 한다.
f. ORDER BY 절에는 '첫 번째 SELECT 절'의 컬럼명, 별칭, 위치표기법을 사용한다.
A. 합집합
a. UNION : 중복제거 + 내부적 정렬
b. UNION ALL : 중복포함 + 내부적 정렬X
SELECT employee_id, job_id, salary
FROM hr.employees;
SELECT employee_id, job_id
FROM hr.job_history;
# 오류 발생, 컬럼 수가 맞지 않음.
SELECT employee_id, job_id, salary
FROM hr.employees
UNION
SELECT employee_id, job_id
FROM hr.job_history;
# 열, 타입의 수 맞춤
SELECT employee_id, job_id, salary
FROM hr.employees
UNION
SELECT employee_id, job_id, NULL
FROM hr.job_history;
# "salary" 타입이 number 타입으로 숫자 0 으로 맞춤
SELECT employee_id, job_id, salary
FROM hr.employees
UNION
SELECT employee_id, job_id, 0
FROM hr.job_history;
# 오류발생, "salary" number type != "문자" char type
SELECT employee_id, job_id, salary
FROM hr.employees
UNION
SELECT employee_id, job_id, '무급'
FROM hr.job_history;
# '무급'인 문자타입을 NUMBER 으로 변경이 어려우므로, "SALARY" 을 TO_CHAR으로 변경
SELECT employee_id, job_id, TO_CHAR(salary)
FROM hr.employees
UNION
SELECT employee_id, job_id, '무급'
FROM hr.job_history;
# 첫 번째 줄 컬럼명에 별칭으로 설정하면 실행창에 출력, 두 번째 줄에 컬럼명에 별칭을 설정하면 실행창에 출력이 되지 않음.
SELECT employee_id AS id, job_id AS job, TO_CHAR(salary)
FROM hr.employees
UNION
SELECT employee_id, job_id, '무급' AS sal
FROM hr.job_history;
# 중복제거(= distinct ), 정렬발생
SELECT employee_id
FROM hr.employees
UNION ALL
SELECT employee_id
FROM hr.job_history;
# 중복포함
SELECT employee_id
FROM hr.employees
UNION ALL
SELECT employee_id
FROM hr.job_history
ORDER BY 1;
# ORDER BY 별칭
SELECT employee_id ID
FROM hr.employees
UNION ALL
SELECT employee_id
FROM hr.job_history
ORDER BY 1;
# ORDER BY 위치표기법
SELECT employee_id AS id, job_id AS job, TO_CHAR(salary) AS sal
FROM hr.employees
UNION ALL
SELECT employee_id, job_id, '무급'
FROM hr.job_history
ORDER BY 3 DESC;
# '무급' 만 출력해주세요. WHERE 절
SELECT *
FROM( SELECT employee_id AS id, job_id AS job, TO_CHAR(salary) AS sal
FROM hr.employees
UNION ALL
SELECT employee_id, job_id, '무급'
FROM hr.job_history
ORDER BY 3 DESC )
WHERE sal = '무급';
B. 교집합
SELECT employee_id
FROM hr.employees
INTERSECT
SELECT employee_id
FROM hr.job_history;
SELECT employee_id, job_id
FROM hr.employees
INTERSECT
SELECT employee_id, job_id
FROM hr.job_history;
C. 차집합 : TABLE 위치가 중요
SELECT employee_id
FROM hr.employees
MINUS
SELECT employee_id
FROM hr.job_history;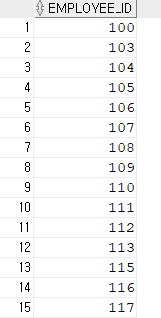
SELECT employee_id, job_id
FROM hr.employees
MINUS
SELECT employee_id, job_id
FROM hr.job_history;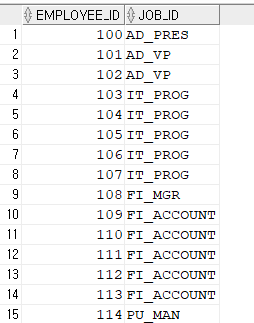
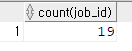
SELECT COUNT(*) "count(job_id)"
FROM (
SELECT job_id
FROM hr.jobs
INTERSECT
SELECT job_id
FROM hr.employees
);
[문제] job_id 를 한번이라도 바꾼 사원들의 정보를 출력해주세요
SELECT *
FROM hr.employees
WHERE employee_id 비교연산자 ( job_id = "한번이라도 바꾼 사원" );" + "
SELECT employee_id
FROM hr.job_history;" = "
# 서브쿼리문에서 중복값 발생
SELECT *
FROM hr.employees
WHERE employee_id IN ( SELECT employee_id
FROM hr.job_history );
# EXISTS (BEST!)
SELECT *
FROM hr.employees e
WHERE EXISTS ( SELECT 'X'
FROM hr.job_history
WHERE employee_id = e.employee_id );
# 집합 연산자 (INTERSECT)
SELECT employee_id
FROM hr.employees
INTERSECT
SELECT employee_id
FROM hr.job_history;
# 비효율적인 쿼리문(가능은 하나, 비효율성)
SELECT *
FROM hr.employees
WHERE employee_id IN ( SELECT employee_id
FROM hr.employees
INTERSECT
SELECT employee_id
FROM hr.job_history );
[문제] job_id 를 한번이라도 바꾸지 않은 사원들의 정보를 출력해주세요
# NOT IN 연산자 문제점: 동일한 TABLE 사용.
SELECT *
FROM hr.employees
WHERE employee_id NOT IN ( SELECT employee_id
FROM hr.job_history );
# IN 연산자 + MINUS (차집합)
SELECT *
FROM hr.employees
WHERE employee_id IN ( SELECT employee_id
FROM hr.employees
MINUS
SELECT employee_id
FROM hr.job_history );
# NOT EXISTS (BEST!)
SELECT *
FROM hr.employees e
WHERE NOT EXISTS ( SELECT 'X'
FROM hr.job_history
WHERE employee_id = e.employee_id );
# 집합 연산자, 차집합 (MINUS)
SELECT employee_id
FROM hr.employees
MINUS
SELECT employee_id
FROM hr.job_history;
[문제] 부서가 소재하지 않은 국가 리스트가 필요하다. COUNTRY_ID, COUNTRY_NAME 출력해주세요
# 집합연산자(MINUS)
SELECT country_id, country_name
FROM hr.countries
MINUS
SELECT c.country_id, c.country_name
FROM hr.departments d, hr.locations l, hr.countries c
WHERE d.location_id = l.location_id
AND l.country_id = c.country_id;
# NOT EXISTS
SELECT country_id, country_name
FROM hr.countries c
WHERE NOT EXISTS ( SELECT 'X'
FROM hr.departments d, hr.locations l
WHERE d.location_id = l.location_id
AND l.country_id = c.country_id )
ORDER BY 2;
#오류발생, FULL OUTER JOIN ON
SELECT e.employee_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id(+) = d.department_id(+);
# 합집합, 문제점: 비효율적(TABLE 2번 사용), 중복제거를 위해서 '정렬'이용
→ 해결방법 : FULL OUTER JOIN ON
SELECT e.employee_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id(+)
UNION
SELECT e.employee_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id(+) = d.department_id;# 해결 쿼리문
SELECT e.employee_id, d.department_name
FROM hr.employees e FULL OUTER JOIN hr.departments d
ON e.department_id = d.department_id;
SELECT e.employee_id, d.department_name
FROM hr.employees e FULL OUTER JOIN hr.departments d
ON e.department_id = d.department_id;
[문제] 아래의 쿼리문을 UNION -> UNION ALL + NOT EXISTS 변환. '정렬' 행위를 줄이기 위해
# 문제점: 중복포함
SELECT e.employee_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id(+)
UNION
SELECT e.employee_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id(+) = d.department_id;
# 소속사원이 없는 부서정보
SELECT *
FROM hr.departments d
WHERE NOT EXISTS ( SELECT 'X'
FROM hr.employees
WHERE department_id = d.department_id );
# 문제: 동일한 TABLE 을 2번 사용.
→ 해결방법 : FULL OUTER JOIN ON
SELECT e.employee_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id(+)
UNION ALL
SELECT NULL, department_name
FROM hr.departments d
WHERE NOT EXISTS ( SELECT 'X'
FROM hr.employees
WHERE department_id = d.department_id );
# 해결 쿼리문
SELECT e.employee_id, d.department_name
FROM hr.employees e FULL OUTER JOIN hr.departments d
ON e.department_id = d.department_id;
[문제]
1) department_id, job_id, manager_id 기준으로 총액 급여를 출력
SELECT department_id, job_id, manager_id, SUM(salary)
FROM hr.employees
GROUP BY department_id, job_id, manager_id;
2) department_id, job_id 기준으로 총액 급여를 출력
SELECT department_id, job_id, SUM(salary)
FROM hr.employees
GROUP BY department_id, job_id;
3) department_id 기준으로 총액 급여 출력
SELECT department_id, SUM(salary)
FROM hr.employees
GROUP BY department_id;
4) 전체 총액 급여를 출력
SELECT SUM(salary)
FROM hr.employees;
1), 2), 3), 4) 를 한꺼번에 출력해주세요.
SELECT department_id, job_id, manager_id, SUM(salary)
FROM hr.employees
GROUP BY department_id, job_id, manager_id
UNION ALL
SELECT department_id, job_id, NULL, SUM(salary)
FROM hr.employees
GROUP BY department_id, job_id
UNION ALL
SELECT department_id, NULL, NULL, SUM(salary)
FROM hr.employees
GROUP BY department_id
UNION ALL
SELECT NULL, NULL, NULL, SUM(salary)
FROM hr.employees;
| GROUP BY 절 | |||
| ROLLUP | CUBE | GROUPING SETS | |
| 해석 | 열 리스트를 그룹화 만드는 연산자 |
모든 컬럼을 그룹화 하는 연산자 |
원하는 컬럼을 그룹화 하는 연산자 |
| 문법 | GROUP BY ROLLUP ( a, b, c ) | GROUP BY CUBE ( a, b, c ) | GROUP BY GROUPING SET ( (a, b), (a, c), () ) |
| 그룹화 | (a, b, c) (a, b) (a) ( 전체 집계값 ) |
(a, b, c) (a, b) ,(a, c), (b, c) (a), (b), (c) ( 전체 집계값 ) |
(a, b) (a, c) ( 전체 집계값 ) |
■ ROLLUP
a. GROUP BY 절에 지정된 열 리스트를 오른쪽에서 왼쪽 방향으로 이동하면서 그룹화를 만드는 연산자
b. UNION ALL 의 편리성
SELECT department_id, job_id, manager_id, SUM(salary)
FROM hr.employees
GROUP BY ROLLUP(department_id, job_id, manager_id)
ORDER BY 1;
■ CUBE
a. ROLLUP 연산자 기능을 포함하고 모든 그룹화를 할 수 있도록 만드는 연산자
SELECT department_id, job_id, manager_id, SUM(salary)
FROM hr.employees
GROUP BY CUBE(department_id, job_id, manager_id);
EX#) 필요한 집계값을 희망한다면? ROLLUP VS CUBE → 둘다 NO
SELECT a, b, c, SUM(sal)
FROM dual
GROUP BY a, b, c;
SUM(sal) = {a, b}
= {a, c}
→ 해결: UNION ALL 로
SELECT a, b, NULL, SUM(sal)
FROM dual
GROUP BY a, b
UNION ALL
SELECT a, NULL, c, SUM(sal)
FROM dual
GROUP BY a, c;
■ GROUPING SETS
a. 내가 원하는 그룹을 만드는 연산자
SELECT department_id, job_id, manager_id, SUM(salary)
FROM hr.employees
GROUP BY GROUPING SETS((department_id, job_id), (department_id, manager_id), ());
[문제] 년도 분기별 총액을 구하세요. 행의 합과 열의 합도 구하세요.
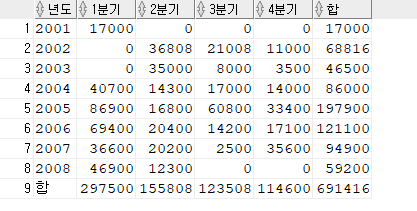
1#. 년도, 분기별 출력
SELECT
to_char(hire_date, 'yyyy') year,
to_char(hire_date, 'q') quarter,
SUM(salary) sumsal
FROM hr.employees
GROUP BY to_char(hire_date, 'yyyy'), to_char(hire_date, 'q');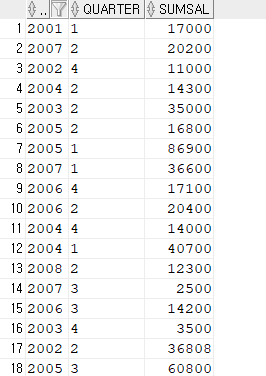
2#. 합계 출력 : GROUP BY CUBE()
SELECT
to_char(hire_date, 'yyyy') year,
to_char(hire_date, 'q') quarter,
SUM(salary) sumsal
FROM hr.employees
GROUP BY CUBE( to_char(hire_date, 'yyyy'), to_char(hire_date, 'q') );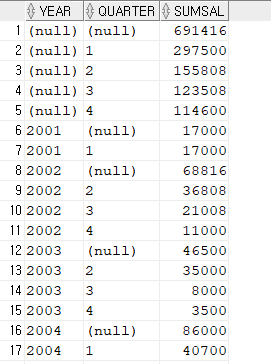
3#. 분기 → null 값을 0으로 변경
SELECT year 년도, nvl(quarter, 0) quarter, sumsal
FROM ( SELECT
to_char(hire_date, 'yyyy') year,
to_char(hire_date, 'q') quarter,
SUM(salary) sumsal
FROM hr.employees
GROUP BY CUBE( to_char(hire_date, 'yyyy'), to_char(hire_date, 'q') ));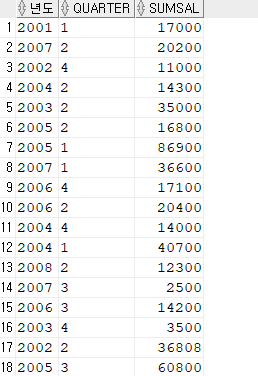
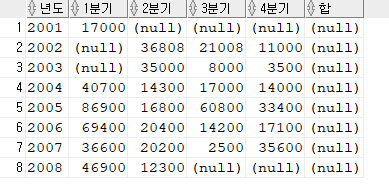
4#-1) 가로로 출력, PIVOT 이용
SELECT *
FROM ( SELECT year 년도, nvl(quarter, 0) quarter, sumsal
FROM ( SELECT
to_char(hire_date, 'yyyy') year,
to_char(hire_date, 'q') quarter,
SUM(salary) sumsal
FROM hr.employees
GROUP BY CUBE( to_char(hire_date, 'yyyy'), to_char(hire_date, 'q') )))
PIVOT ( MAX(sumsal) FOR quarter IN (1 "1분기", 2 "2분기", 3 "3분기", 4 "4분기", 0 "합") )
ORDER BY 1;tip) 두 번째 SELECT 절에 있는 "year 년도, nvl(quarter, 0) quarter, sumsal"
nvl(quarter, 0) 은 해당 select 절에만 해당하는 구문이다. 그래서 전체적으로 실행하면 'NULL' 값으로 확인된다.
4#-2)
SELECT NVL(년도, '합') 년도, NVL("1분기",0) "1분기", NVL("2분기",0) "2분기", NVL("3분기",0) "3분기", NVL("4분기",0) "4분기", 합
FROM ( SELECT *
FROM ( SELECT year 년도, nvl(quarter, 0) quarter, sumsal
FROM ( SELECT
to_char(hire_date, 'yyyy') year,
to_char(hire_date, 'q') quarter,
SUM(salary) sumsal
FROM hr.employees
GROUP BY CUBE( to_char(hire_date, 'yyyy'), to_char(hire_date, 'q') )))
PIVOT ( MAX(sumsal) FOR quarter IN (1 "1분기", 2 "2분기", 3 "3분기", 4 "4분기", 0 "합")
)
ORDER BY 1);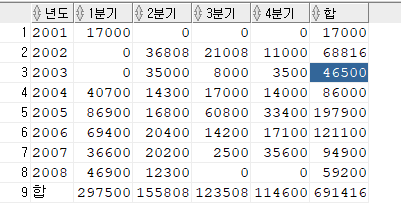
위와 아래의 쿼리문 차이는 PIVOT의 IN 에서의 별칭 차이이다.
PIVOT 절에서 별칭에서 영문으로 작성한 다음에 첫 번째 SELECT 절에서 컬럼명 별칭을 보기 좋게 변경해 주는 것이 좋다!
4#-3)
SELECT NVL(년도, '합') 년도, NVL("Q1",0) "1분기", NVL("Q2",0) "2분기", NVL("Q3",0) "3분기", NVL("Q4",0) "4분기", 합
FROM ( SELECT *
FROM ( SELECT year 년도, nvl(quarter, 0) quarter, sumsal
FROM ( SELECT
to_char(hire_date, 'yyyy') year,
to_char(hire_date, 'q') quarter,
SUM(salary) sumsal
FROM hr.employees
GROUP BY CUBE( to_char(hire_date, 'yyyy'), to_char(hire_date, 'q') )))
PIVOT ( MAX(sumsal) FOR quarter IN (1 "Q1", 2 "Q2", 3 "Q3", 4 "Q4", 0 "합")
/* 한글보다 영문으로 별칭 작성하는게 더 편함 */
)
ORDER BY 1);'Data Base > Oracle SQL' 카테고리의 다른 글
| 231018 Oracle SQL WITH문 (1) | 2023.10.18 |
|---|---|
| 23.10.17. Oracle SQL 계층 검색(hierarchical query) START WITH-CONNECT BY PRIOR (0) | 2023.10.17 |
| 23.10.16. Oracle SQL PIVOT, UNPIVOT, 다중열 서브쿼리(비쌍비교 VS 쌍비교), SCALAR SUBQUERY(스칼라 서브쿼리) (1) | 2023.10.16 |
| 23.10.13. Oracle SQL IN, ANY, ALL (0) | 2023.10.13 |
| 23.10.13. Oracle SQL SUBQUERY(서브쿼리) (0) | 2023.10.13 |