[문제1] 입사한 월을 출력하고 월별 입사자 수를 1월부터 12월 까지 순서대로 출력하시오.
SELECT to_char(hire_date, 'mm"월"') 입사한월, count(*)
FROM hr.employees
GROUP by to_char(hire_date, 'mm"월"')
ORDER BY 1;
정답)
A.
SELECT month||'월' 월, cnt 인원수
FROM ( SELECT to_number(to_char(hire_date, 'mm')) month , count(*) cnt
FROM hr.employees
GROUP by to_number(to_char(hire_date, 'mm'))
ORDER BY 1 );B.
SELECT month||'월' 월, cnt 인원수
FROM ( SELECT extract(month from hire_date) month , count(*) cnt
FROM hr.employees
GROUP by extract(month from hire_date)
ORDER BY 1 );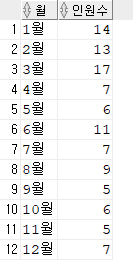
'내 멋대로'의 해석)
문제에는 '1월부터 12월' 까지 순서대로 써있는데, 나는 출력할 때, '01월부터 12월' 로 출력을 해버렸다..!
값은 달라지는 것이 아니지만, 문제에 맞게 출력을 해보자!
[문제2] 근속연수가 가장 긴 10위까지 사원들의 employee_id, last_name, hire_date를 출력하세요. (연이은 순이를 구하세요)
SELECT *
FROM ( SELECT
employee_id,
last_name,
hire_date,
trunc(months_between(sysdate, hire_date)/12) 근속연수,
dense_rank() over(order by hire_date) dense_rank
FROM hr.employees )
WHERE dense_rank <=10 ;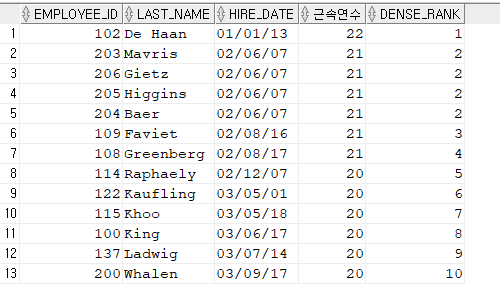
정답)
SELECT *
FROM ( SELECT
employee_id,
last_name,
hire_date,
dense_rank() over(order by hire_date) rank
FROM hr.employees )
WHERE RANK <= 10;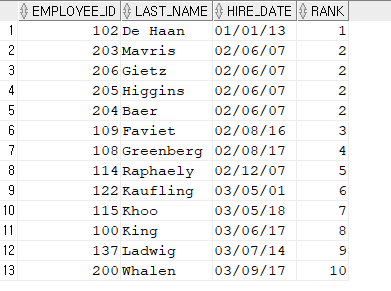
'내 멋대로'의 해석)
문제에서는 '연이은 순이' 를 구하라고 한다. 그것은 dense_rank() over() 을 통해 순위를 구하라는 문제!
★ [문제3] 아래화면과 같이 급여의 도수분포표를 생성하세요.
(실행창)
| 계급 | 도수 |
| 2000~5000 | 49 |
| 5001~10000 | 43 |
| 10001~15000 | 12 |
| 15001~20000 | 2 |
| 20001~ | 1 |
select salary "계급", count(*) over(partition by salary) "도수"
from ( select
salary,
case
when salary between 2000 and 5000 then 1
when salary between 5001 and 10000 then 2
when salary between 10001 and 15000 then 3
when salary between 15001 and 20000 then 4
else 5
end
from hr.employees)
group by salary
order by min(salary);
정답)
SELECT *
FROM ( SELECT
count(case when salary between 2000 and 5000 then 'x' end) "2000~5000" ,
count(case when salary between 5001 and 10000 then 'x' end) "5001~10000" ,
count(case when salary between 10001 and 15000 then 'x' end) "10001~15000" ,
count(case when salary between 15001 and 20000 then 'x' end) "15001~20000" ,
count(case when salary > 20000 then 'x' end) "20001~"
FROM hr.employees )
UNPIVOT ( 도수 FOR 계급 IN ("2000~5000", "5001~10000", "10001~15000", "15001~20000", "20001~") );
'내 멋대로'의 해석)
해당 문제는 count 와 case 문, pivot 을 이용해서 하나의 표를 출력하는 문제였다.
난 pivot까지 생각도 못했다..! 문제를 이해를 못한 걸 수도 있다..
[문제4] 15000 이상 급여를 받는 관리자 이름, 급여, 급여등급을 출력하세요.
SELECT e.last_name, e.salary, j.grade_level
FROM hr.employees e, hr.job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal
AND e.salary >= 15000 ;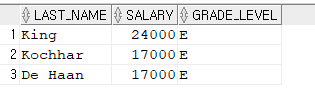
정답)
SELECT e.last_name, e.salary, ( SELECT grade_level
FROM hr.job_grades
WHERE e.salary BETWEEN lowest_sal AND highest_sal ) grade_level
FROM hr.employees e
WHERE EXISTS ( SELECT 'X'
FROM hr.employees
WHERE manager_id = e.employee_id )
AND e.salary >= 15000;'내 멋대로'의 해석)
join문으로는 생각할 수 있다. 하지만, 성능이 저하가 되어 좋지 않은 쿼리문이라 들었다.
현재는 많지 않는 data로 join문을 써도 괜찮을지 모르겠지만, 실무적으로 사용할 때에는 스칼라서브쿼리와 EXISTS 문을 활용한 문장을 쓰는 것이 더 좋다.
[문제5] 년도 분기별 급여 총액을 출력하세요.
SELECT *
FROM ( SELECT to_char(hire_date, 'yyyy') 년도, to_char(hire_date, 'q') 분기, SUM(salary) 총액
FROM hr.employees
GROUP BY to_char(hire_date, 'yyyy'), to_char(hire_date, 'q'))
PIVOT ( MAX(총액) FOR 분기 IN (1 AS "1분기", 2 "2분기", 3 "3분기", 4 "4분기") )
ORDER BY 1;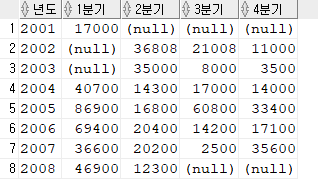
정답)
A.
SELECT *
FROM ( select
to_char(hire_date, 'yyyy') 년도,
sum(decode(to_char(hire_date, 'q'), 1, salary)) "1분기",
sum(decode(to_char(hire_date, 'q'), 2, salary)) "2분기",
sum(decode(to_char(hire_date, 'q'), 3, salary)) "3분기",
sum(decode(to_char(hire_date, 'q'), 4, salary)) "4분기"
from hr.employees
group by to_char(hire_date, 'yyyy') )
ORDER BY 1;B.
SELECT *
FROM ( SELECT to_char(hire_date, 'yyyy' ) 년도, to_char(hire_date, 'q') quarter, salary
FROM hr.employees )
PIVOT ( sum(salary) FOR quarter IN ('1' "1분기", '2' "2분기", '3' "3분기", '4' "4분기") )
ORDER by 1;'내 멋대로'의 해석)
수업시간에 한 번 했던 쿼리문이다. 긴 쿼리문도 짧게 할 수 있다는 걸 알아두자!
[문제6] 같은 부서에서 last_name이 같은 사원들을 찾아주세요.
SELECT *
FROM ( SELECT department_id, last_name
FROM hr.employees
GROUP BY department_id, last_name
HAVING count(*) > 1 ) e1 , hr.employees e2
WHERE e1.last_name = e2.last_name
AND e1.department_id = e2.department_id;
정답)
SELECT *
FROM hr.employees e
WHERE EXISTS ( SELECT 'X'
FROM hr.employees
WHERE department_id = e.department_id
AND last_name = e.last_name
AND employee_id <> e.employee_id );
'내 멋대로'의 해석)
같은 실행값이나, 내가 쓴 쿼리문이 왜.. 더 복잡해 보이는건가..
먼저, 존재여부를 체크한 후에 그 이후에 출력하는 것이 더 낫다는 강사님의 말씀.. ㅎㅎ
[문제7] 사원수가 3명 미만인 부서번호,부서이름,인원수를 출력해주세요.
SELECT e.department_id, d.department_name , e.cnt
FROM ( SELECT department_id, count(*) cnt
FROM hr.employees
GROUP by department_id
HAVING count(*) < 3) e, hr.departments d
WHERE e.department_id = d.department_id;
정답)
SELECT e.department_id 부서번호, d.department_name 부서이름, e.cnt 인원수
FROM ( SELECT department_id, count(*) cnt
FROM hr.employees
GROUP by department_id
HAVING count(*) < 3 ) e, hr.departments d
WHERE e.department_id = d.department_id;
'내 멋대로'의 해석)
각 컬럼의 별칭을 써주면 보고할 때 편하다 했다..!
[문제8] 사원 수가 가장 많은 부서정보, 도시, 인원수를 출력해주세요.
WITH
dept_cnt AS ( SELECT department_id, count(*) cnt
FROM hr.employees
GROUP BY department_id ),
dept_cnt_max AS ( SELECT MAX(cnt) max_cnt FROM dept_cnt )
SELECT d2.*, l.city, d1.cnt 인원수
FROM dept_cnt d1, hr.departments d2, hr.locations l
WHERE d1.department_id = d2.department_id
AND d2.location_id = l.location_id
AND d1.cnt = ( SELECT max_cnt FROM dept_cnt_max );
정답)
A.
SELECT d.*, l.city, e.cnt
FROM ( SELECT department_id, count(*) cnt
FROM hr.employees
GROUP by department_id
HAVING count(*) = ( SELECT max(count(*))
FROM hr.employees
GROUP by department_id )
-- FROM 절 : 소속 사원이 많은 출력값, 동일한 테이블을 2번이상 쓰지 않는 것이 best!
) e, hr.departments d, hr.locations l
WHERE e.department_id = d.department_id
AND d.location_id = l.location_id ;B.
WITH
dept_cnt AS ( SELECT department_id, count(*) cnt
FROM hr.employees
GROUP by department_id)
SELECT d.*, l.city, c.cnt
FROM dept_cnt c, hr.departments d, hr.locations l
WHERE cnt = ( SELECT max(cnt) FROM dept_cnt )
AND c.department_id = d.department_id
AND d.location_id = l.location_id ;'내 멋대로'의 해석)
A와 B의 같은 실행창이여도 성능 차이가 있다고 한다. DATA가 많을 수록 같은 테이블을 2번 이상 쓰지 않는 것이 가장 BEST!
[문제9] 요일별 입사한 인원수를 출력해주세요.
SELECT to_char(hire_date, 'day') day , count(*) 인원수
FROM hr.employees
GROUP BY to_char(hire_date, 'day') ;
정답)
SELECT decode(day, 1, '일', 2, '월', 3, '화', 4, '수', 5, '목', 6, '금', 7, '토') 요일, cnt 인원수
FROM ( SELECT to_char(hire_date, 'd') day, count(*) cnt
FROM hr.employees
GROUP BY to_char(hire_date, 'd')
ORDER BY 1);
# 가로방향 : PIVOT
SELECT *
FROM ( SELECT to_char(hire_date, 'd') day
FROM hr.employees )
PIVOT ( COUNT(*) FOR day IN (1 "일", 2 "월", 3 "화", 4 "수", 5 "목", 6 "금", 7 "토") );
# 세로방향 : UNPIVOT
SELECT *
FROM ( SELECT *
FROM ( SELECT to_char(hire_date, 'd') day
FROM hr.employees )
PIVOT ( COUNT(*) FOR day IN (1 "일", 2 "월", 3 "화", 4 "수", 5 "목", 6 "금", 7 "토") ))
UNPIVOT ( 인원수 FOR 요일 IN ("일", "월", "화", "수", "목", "금", "토") );'내 멋대로'의 해석)
요일을 출력할 때에는 숫자로 출력하는 방법과 문자로 출력하는 방법이 있다.
나는 문자로 출력하는 방법을 선택했다. 문자형태이다 보니, ㄱㄴㄷ 형태로 ORDER BY 절로 정렬이 된다.
[문제10] 부서별 최고 급여자의 사원들을 출력해주세요.
SELECT e1.department_id , e1.salary , e1.last_name
FROM hr.employees e1, ( SELECT department_id , MAX(salary) max_sal
FROM hr.employees
GROUP BY department_id ) e2
WHERE e1.department_id = e2.department_id
AND e1.salary = e2.max_sal ;
정답)
A.
SELECT e2.*
FROM ( SELECT department_id, max(salary) maxsal
FROM hr.employees
GROUP BY department_id ) e1, hr.employees e2
WHERE e1.department_id = e2.department_id
AND e1.maxsal = e2.salary;B.
SELECT *
FROM hr.employees
WHERE (department_id, salary) IN ( SELECT department_id, max(salary) maxsal
FROM hr.employees
GROUP BY department_id );
C.
SELECT *
FROM ( SELECT
employee_id, last_name, salary, department_id ,
MAX(salary) OVER(partition by department_id) maxsal ,
case when salary = MAX(salary) OVER(partition by department_id) then 'x' end case_sal
FROM hr.employees
ORDER BY 4 )
WHERE case_sal = 'x';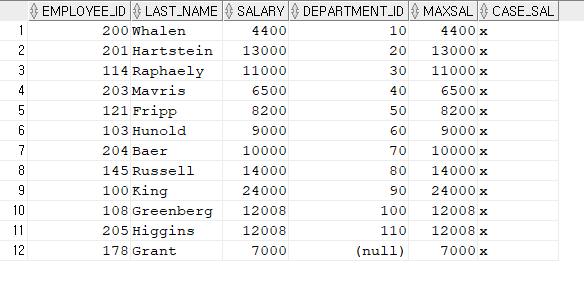
'내 멋대로'의 해석)
내가 푼 방식은 INLINE VIEW 로 했다.
1. 부서별 최고 급여의 사원들을 출력. → 그 쿼리문을 SELECT문으로 묶어서 JOIN 으로 진행했다.
2. A 방식도 나와 동일한 INLINE VIEW 방식이다. B 방식은 WHERE절에 IN 연산자를 통해 출력하는 방식이다.
3. C방식은 분석함수인 MAX() OVER() 와 CASE문을 이용해서 출력했다.
'문제 > SQL' 카테고리의 다른 글
| 231027 PL/SQL 복습 겸 문제 (0) | 2023.10.30 |
|---|---|
| 231026 PL/SQL 복습 겸 문제 (1) | 2023.10.26 |
| 231024 Oracle SQL 필기 TEST's 오답노트 (0) | 2023.10.24 |
| 231018 복습 겸 문제 (0) | 2023.10.18 |
| 23.10.17. Class 복습 겸 문제 (1) | 2023.10.17 |