■ sort operation
<hr sess>
select /*+ gather_plan_statistics */ * from employees order by salary desc;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));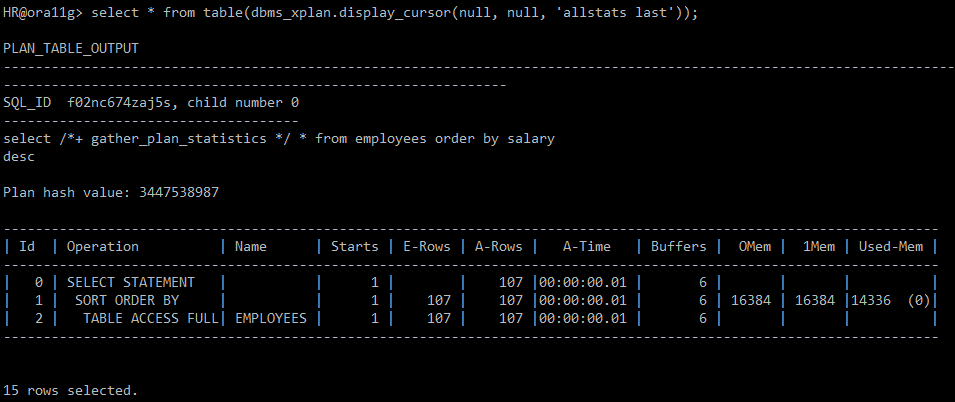
select /*+ gather_plan_statistics */ department_id, sum(salary)
from employees
group by department_id;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));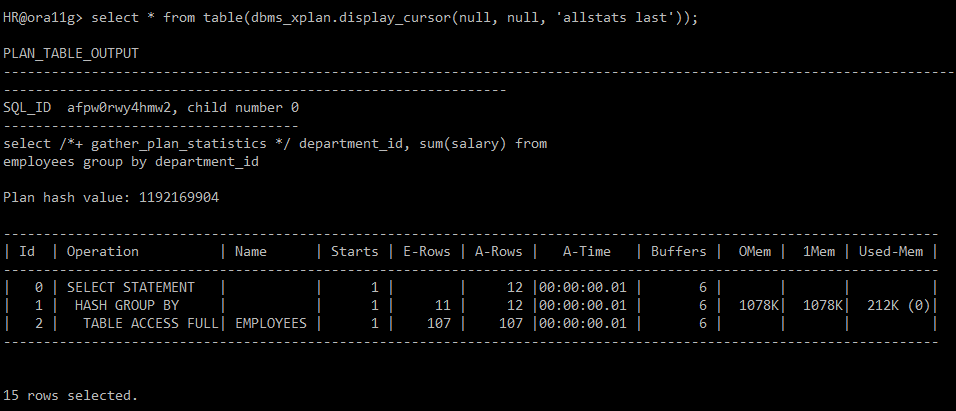
→ HASH GROUP BY : 정렬 되지 않음.
select /*+ gather_plan_statistics */ distinct department_id from employees;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));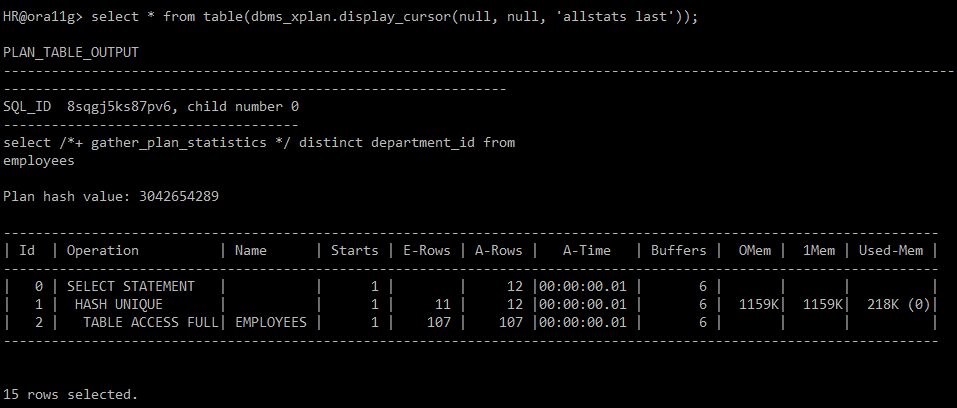
→ HASH UNIQUE: hash 알고리즘이 돌아가고 있다.
<sys sess>
select a.ksppinm name , b.ksppstvl value
from x$ksppi a, x$ksppsv b
where a.indx = b.indx
and a.ksppinm = '_gby_hash_aggregation_enabled';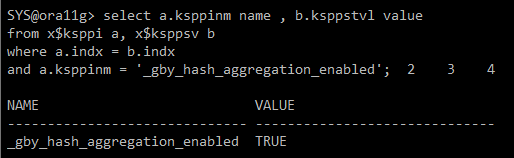
<hr sess>
alter session set "_gby_hash_aggregation_enabled" = false;
select /*+ gather_plan_statistics */ department_id, sum(salary)
from employees
group by department_id;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));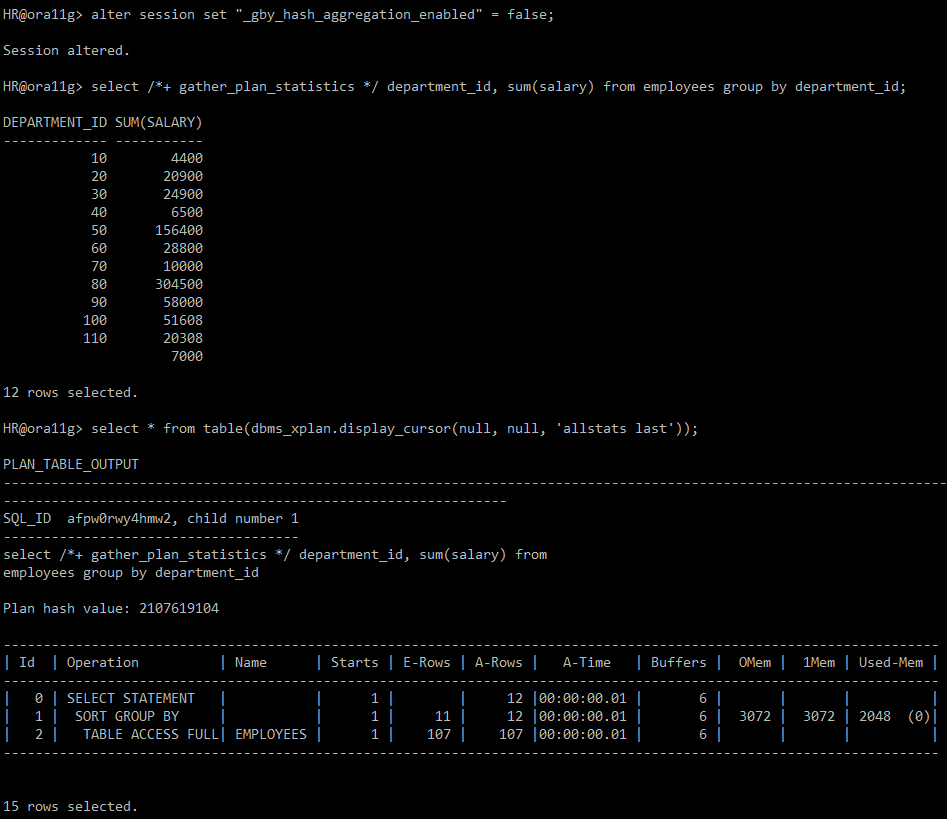
select /*+ gather_plan_statistics */ distinct department_id from employees;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));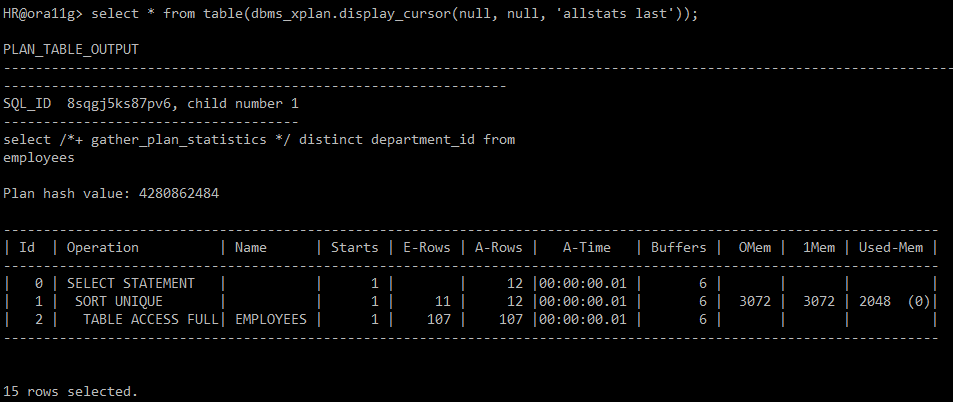
<hr sess>
alter session set "_gby_hash_aggregation_enabled" = true;
#) 정렬 작업
1#) 집합 연산자 | union, minus, intersect
select /*+ gather_plan_statistics */ employee_id, last_name from employees where job_id = 'ST_CLERK'
union
select employee_id, last_name from employees where salary > 10000;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
select /*+ gather_plan_statistics */ employee_id, last_name from employees where job_id = 'ST_CLERK'
minus
select employee_id, last_name from employees where salary > 10000;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
select /*+ gather_plan_statistics */ employee_id, last_name from employees where job_id = 'ST_CLERK'
intersect
select employee_id, last_name from employees where salary > 10000;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
#2) join
select /*+ gather_plan_statistics reading(d e) use_merge(d) */ e.*, d.*
from employees e, departments d
where e.department_id = d.deparment_id;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
#3) 인덱스 생성
ex) create index hr.emp_idx on hr.emp(employee_id);
- 재귀호출
select employee_id
from hr.emp
order by employee_id;
#4) 통계 수집
■ 실행계획
1. data access 방법
2. join 방법
3. join 순서
■ join 방법
1. nested loop join (=: 반복문)
- 조인의 건수가 적을 경우 유리하다.
- 인덱스를 통해서 데이터를 액세스 하는 조인이다.
- 힌트: use_nl
2. sort merge join
- 조인되는 건수가 많을 경우 유리하다.
- sort(sort 알고리즘)에 대한 성능의 문제가 발생할 수 있다.
- 힌트: use_merge
3. hash join
- 조인되는 건수가 많을 경우 유리하다.
- hash 알고리즘 수행된다.
- 힌트: use_hash
■ join 순서에 관련된 힌트
1. ordered: from 절에서 나열된 테이블 순서대로 조인의 순서로 결정된다.
변경하려면 from 절에 있는 table의 위치를 변경해줘야 한다.
2. leading: 힌트 안에 leading 의 나열한 테이블 순서대로 조인의 순서로 결정된다.
<시나리오>
SELECT /*+ gather_plan_statistics */ e.last_name, e.first_name, e.salary, e.job_id, d.department_name
FROM departments d, employees e
WHERE d.department_id = e.department_id
AND e.employee_id = 100;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));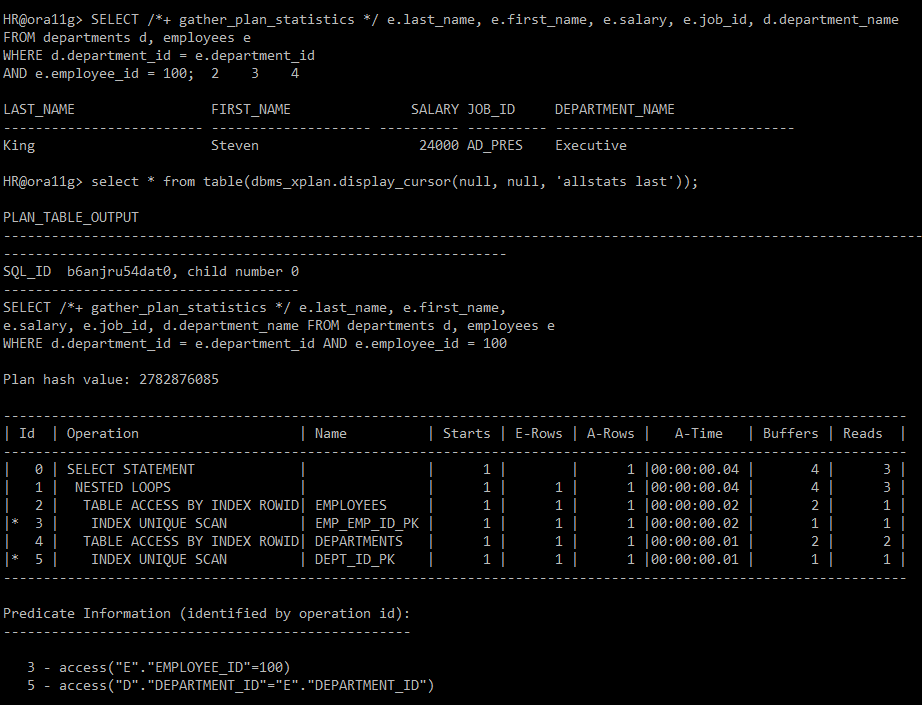
| 2 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 1 | 1 |00:00:00.01 | 2 |
<- outer / driving
|* 3 | INDEX UNIQUE SCAN | EMP_EMP_ID_PK | 1 | 1 | 1 |00:00:00.01 | 1 |
| 4 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 | 1 | 1 |00:00:00.01 | 2 |
<- inner / driving
|* 5 | INDEX UNIQUE SCAN | DEPT_ID_PK | 1 | 1 | 1 |00:00:00.01 | 1 |
<- i/o block 횟수(root-branch-leaf 가 하나의 block 에 있다는 것이다.)
3 - access("E"."EMPLOYEE_ID"=100) -> 2번을 수행해야만 3번 수행이 된다.
5 - access("D"."DEPARTMENT_ID"="E"."DEPARTMENT_ID")=> 수행순서: 3번 -> 2번 -> 5번 -> 4번 -> 1번
#) 힌트 use_nl 사용
SELECT /*+ gather_plan_statistics use_nl(e,d) */ e.last_name, e.first_name, e.salary, e.job_id, d.department_name
FROM departments d, employees e
WHERE d.department_id = e.department_id
AND e.employee_id = 100;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));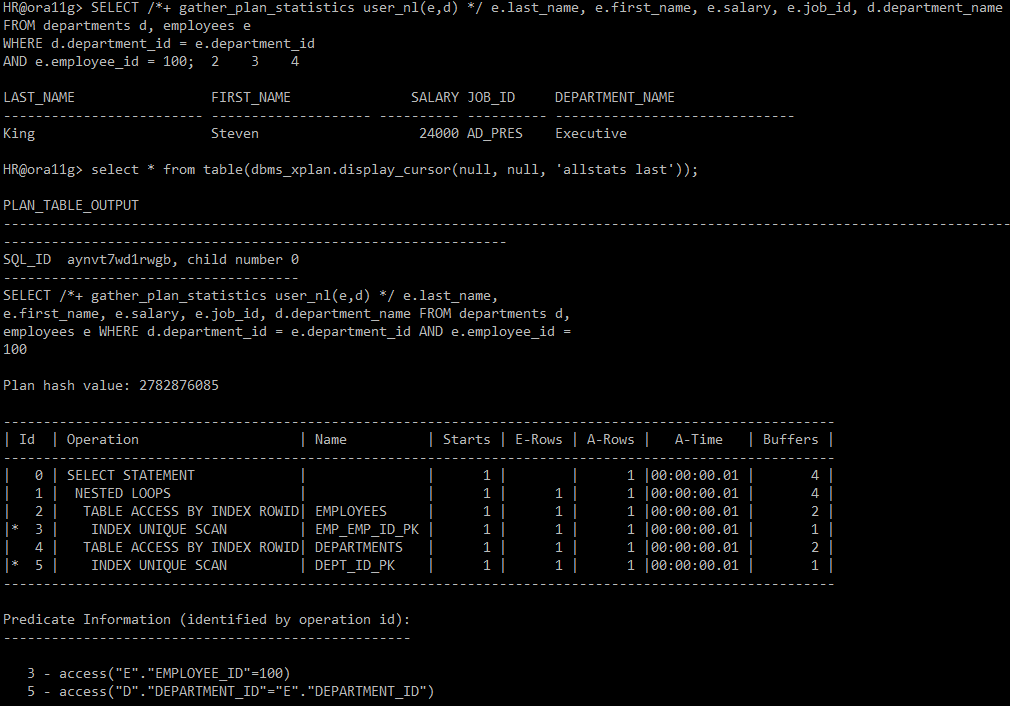
#) 힌트사용: ordered use_nl(d) -> ordered: 별도의 table 별칭 기재 하지 않음 | use_nl(inner table 별칭)
SELECT /*+ gather_plan_statistics ordered use_nl(d) */ e.last_name, e.first_name, e.salary, e.job_id, d.department_name
FROM departments d, employees e
WHERE d.department_id = e.department_id
AND e.employee_id = 100;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));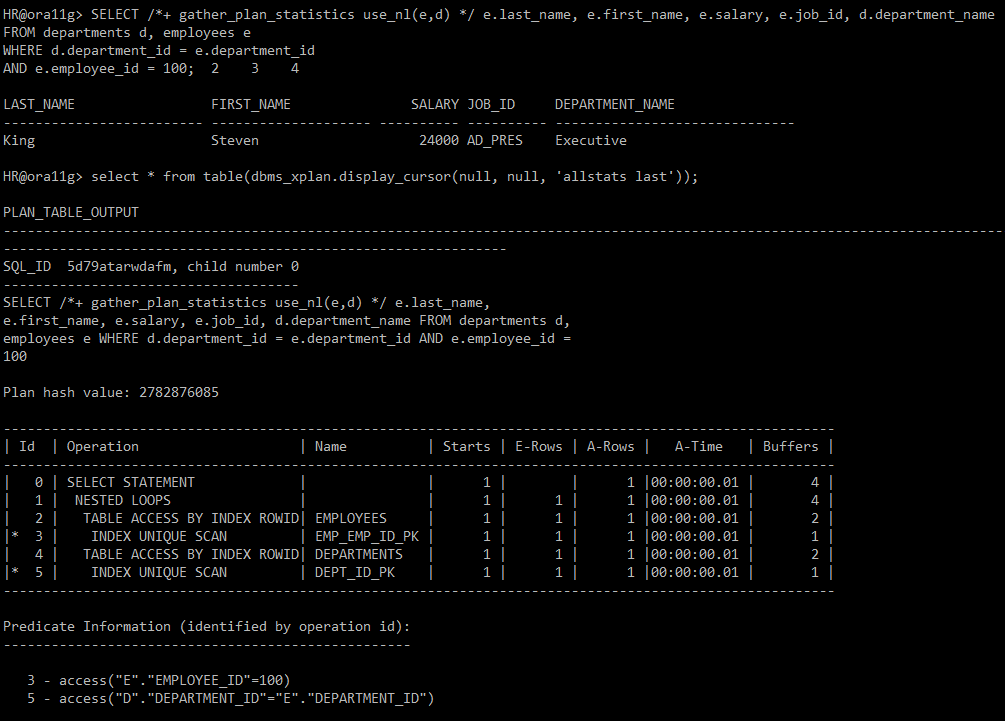
#) 힌트사용: leading(e,d) use_nl(d) -> leading(e,d):순서 직접 변경 가능 | use_nl(inner table 별칭)
SELECT /*+ gather_plan_statistics leading(e,d) use_nl(d) */ e.last_name, e.first_name, e.salary, e.job_id, d.department_name
FROM departments d, employees e
WHERE d.department_id = e.department_id
AND e.employee_id = 100;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));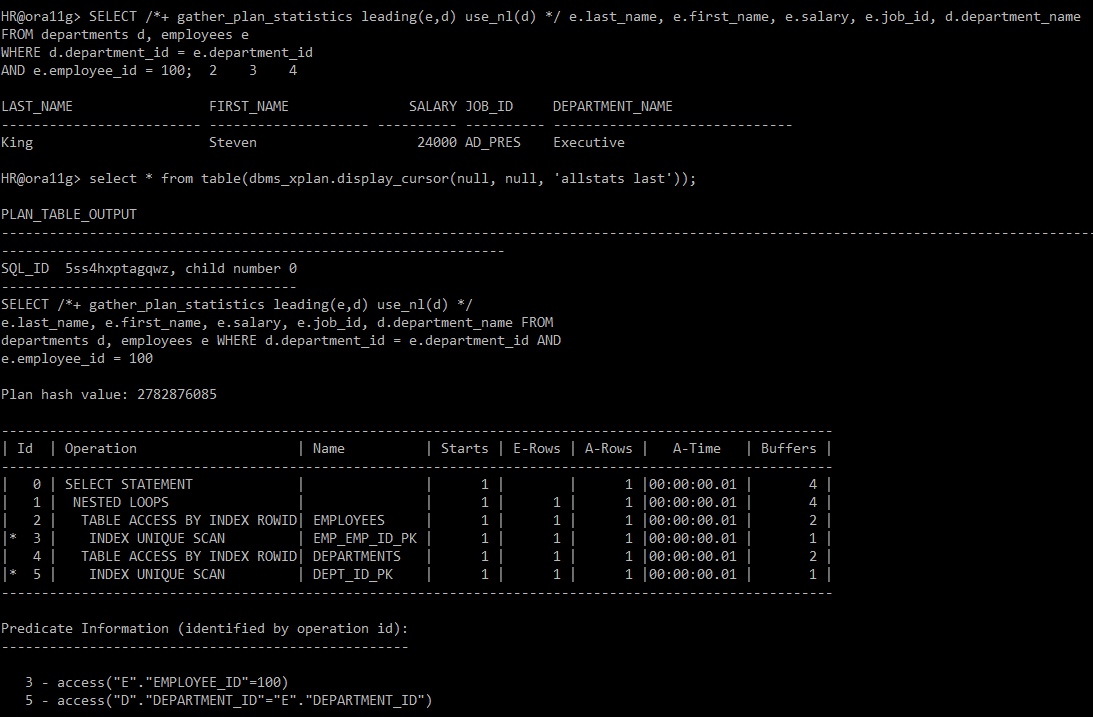
#) 테이블 3개를 조인 했을 경우
SELECT /*+ gather_plan_statistics leading(e,d,l) use_nl(d) use_nl(l) */ e.last_name, e.first_name, e.salary, e.job_id, d.department_name, l.city
FROM departments d, employees e, locations l
WHERE d.department_id = e.department_id
AND d.location_id = l.location_id
AND e.employee_id = 100;
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
※ 먼저 체크 할 것
1. 테이블의 인덱스 체크
select * from user_ind_columns where table_name = 'DEPARTMENTS';
2. 비조인조건술어 해당하는 데이터의 건수
select count(*) from hr.departments where location_id = 2500;
'Data Base > SQL 튜닝' 카테고리의 다른 글
| join 실행 계획 (0) | 2024.02.19 |
|---|---|
| join 문, index 설정 (0) | 2024.02.19 |
| batch i/o, table prefetch, 옵티마이저 (0) | 2024.02.17 |
| PGA, 자동 PGA 메모리 관리 (1) | 2024.02.17 |
| B-Tree 구조, Bitmap 구조 인덱스, session_cached_cursors (0) | 2024.02.17 |