#) 새로 샘플 테이블 생성. (nologging 조건으로 생성)
create table hr.emp
nologging
as
select * from hr.employees;
create table hr.dept
nologging
as
select * from hr.departments;
create table hr.loc
nologging
as
select * from hr.locations;
#) 프로시저 생성
exec dbms_stats.gather_table_stats('hr', 'emp');
exec dbms_stats.gather_table_stats('hr', 'dept');
exec dbms_stats.gather_table_stats('hr', 'loc');

#) 생성 확인
select table_name, num_rows, blocks, avg_row_len, last_analyzed
from user_tables
where table_name in ('EMP', 'DEPT', 'LOC');
#) 제약조건 확인
select * from user_constraints where table_name in ('EMP', 'DEPT', 'LOC') and owner = 'HR';
#) 제약조건 확인
select a.table_name, a.constraint_name, b.column_name, a.constraint_type, a.search_condition, a.r_constraint_name, a.index_name
from user_constraints a, user_cons_columns b
where a.constraint_name = b.constraint_name
and a.table_name in ('EMP', 'DEPT', 'LOC');
#) (낮에 돌아간다면?) join 쿼리문 실행
select /*+ gather_plan_statistics */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.employee_id = 100;
#) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));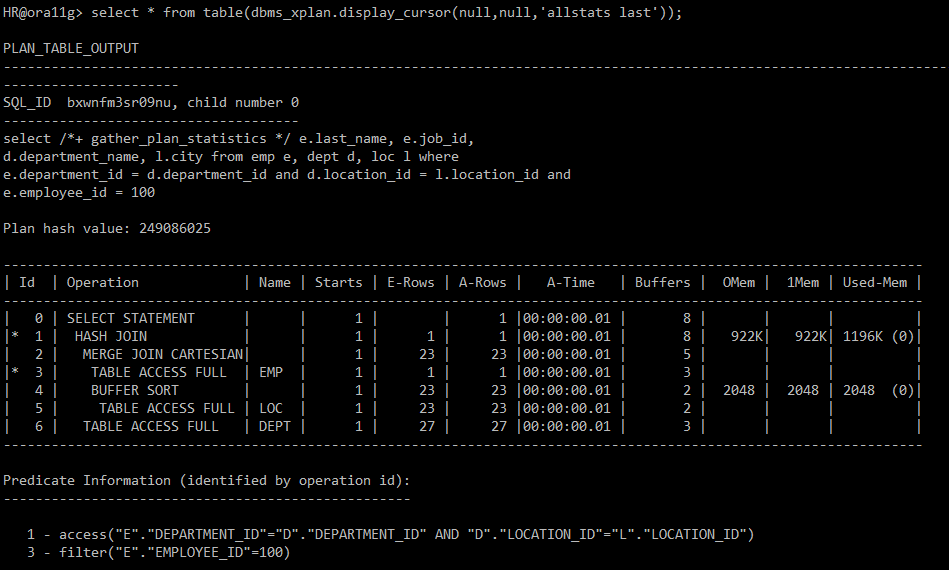
→ 성능 떨어짐 | cup 저하, i/o 떨어짐
→ sort merge join 해결상황: join 순서 변경 or index 생성
# 해결 방안_실행 계획 방법 #
#1) leading() use_nl() 힌트 사용
select /*+ gather_plan_statistics leading(e,d,l) use_nl(d) use_nl(l) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.employee_id = 100;
#) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
-> pga 사용량 없음.
-> 문제: 3,4,5번이 full scan 돌아감.

# 해결방안_인덱스 생성#
#1) 인덱스 확인_emp
select a.table_name, a.constraint_name, b.column_name, a.constraint_type, a.search_condition, a.r_constraint_name, a.index_name
from user_constraints a, user_cons_columns b
where a.constraint_name = b.constraint_name
and a.table_name = 'EMP';

select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'EMP';
#2) 유니크 인덱스 생성 후 primary key 생성
create unique index hr.emp_idx on hr.emp(employee_id);
alter table hr.emp add constraint emp_pk primary key(employee_id) using index hr.emp_idx;
#3) 인덱스 생성 되었는지 확인
select a.table_name, a.constraint_name, b.column_name, a.constraint_type, a.search_condition, a.r_constraint_name, a.index_name
from user_constraints a, user_cons_columns b
where a.constraint_name = b.constraint_name
and a.table_name = 'EMP';
#3) 생성 확인
select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'EMP';
#4) 인덱스(emp) 생성 + leading() use_nl() 힌트 사용
select /*+ gather_plan_statistics leading(e,d,l) use_nl(d) use_nl(l) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.employee_id = 100;
#5) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
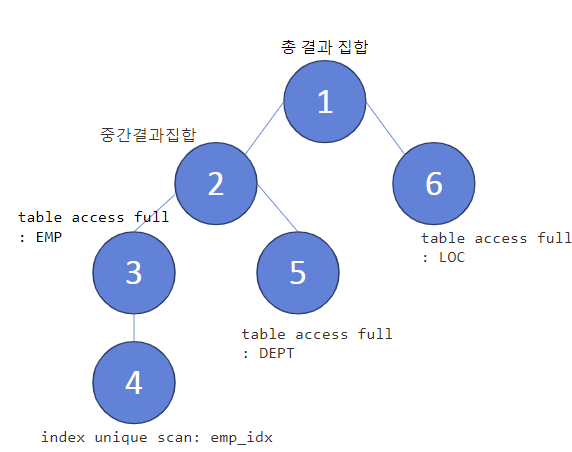
#) department_id 인덱스 생성
#1) 유니크 인덱스 생성 후 primary key 생성
create unique index hr.dept_idx on hr.dept(department_id);
alter table hr.dept add constraint dept_pk primary key(department_id) using index hr.dept_idx;
#2) 제약 조건 확인
select a.table_name, a.constraint_name, b.column_name, a.constraint_type, a.search_condition, a.r_constraint_name, a.index_name
from user_constraints a, user_cons_columns b
where a.constraint_name = b.constraint_name
and a.table_name = 'DEPT';
select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'DEPT';
#3) 인덱스(dept) 생성 + leading() use_nl() 힌트 사용
select /*+ gather_plan_statistics leading(e,d,l) use_nl(d) use_nl(l) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.employee_id = 100;
#4) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));

#) location의 location_id 인덱스 생성
#1) 유니크 인덱스 생성 후 primary key 생성
create unique index hr.loc_idx on hr.loc(location_id);
alter table hr.loc add constraint loc_pk primary key(location_id) using index hr.loc_idx;
#2) 제약 조건 확인
select a.table_name, a.constraint_name, b.column_name, a.constraint_type, a.search_condition, a.r_constraint_name, a.index_name
from user_constraints a, user_cons_columns b
where a.constraint_name = b.constraint_name
and a.table_name = 'LOC';
select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'LOC';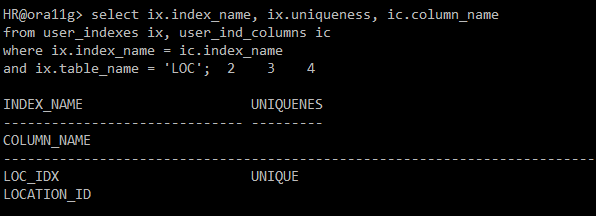
#3) 인덱스(dept) 생성 + leading() use_nl() 힌트 사용
select /*+ gather_plan_statistics leading(e,d,l) use_nl(d) use_nl(l) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id /* 2. inner인 department_id 에 index 설정되어 있어야 함 */
and d.location_id = l.location_id /* 3. location_id 에 index 설정되어 있어야 함 */
and e.employee_id = 100; /* 1. otter에 먼저 index 설정되어 있어야 함 */
#4) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
=> 처음보다는 i/o 줄어듬!
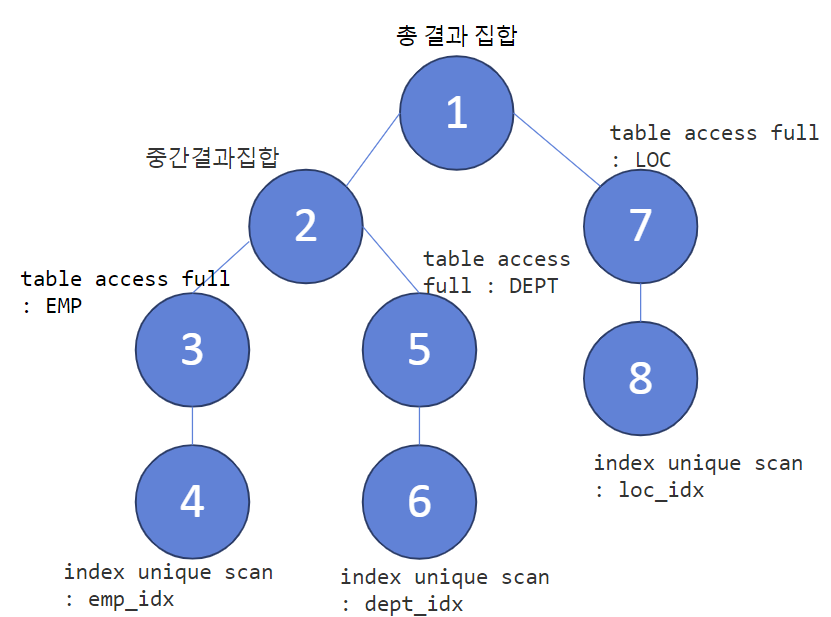
# test 해보기 #
select /*+ gather_plan_statistics */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and l.city = 'Seattle';
#) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
→ (해결 방안) join 의 위치를 변경.
# 해결방안_join 위치 변경
#1) city = 'Seattle' 의 건수 확인
select count(*) from loc where city = 'Seattle';
#2) leaging()을 통해 join 위치 변경해준다. use_nl() 힌트 사용
select /*+ gather_plan_statistics leading(l,d,e) use_nl(d) use_nl(e) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and l.city = 'Seattle';
#3) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
Id. 3번 : outter -> 3block + latch 3번 잡음
Id. 4번: inner
Id. 5번 : 65번의 i/o 발생

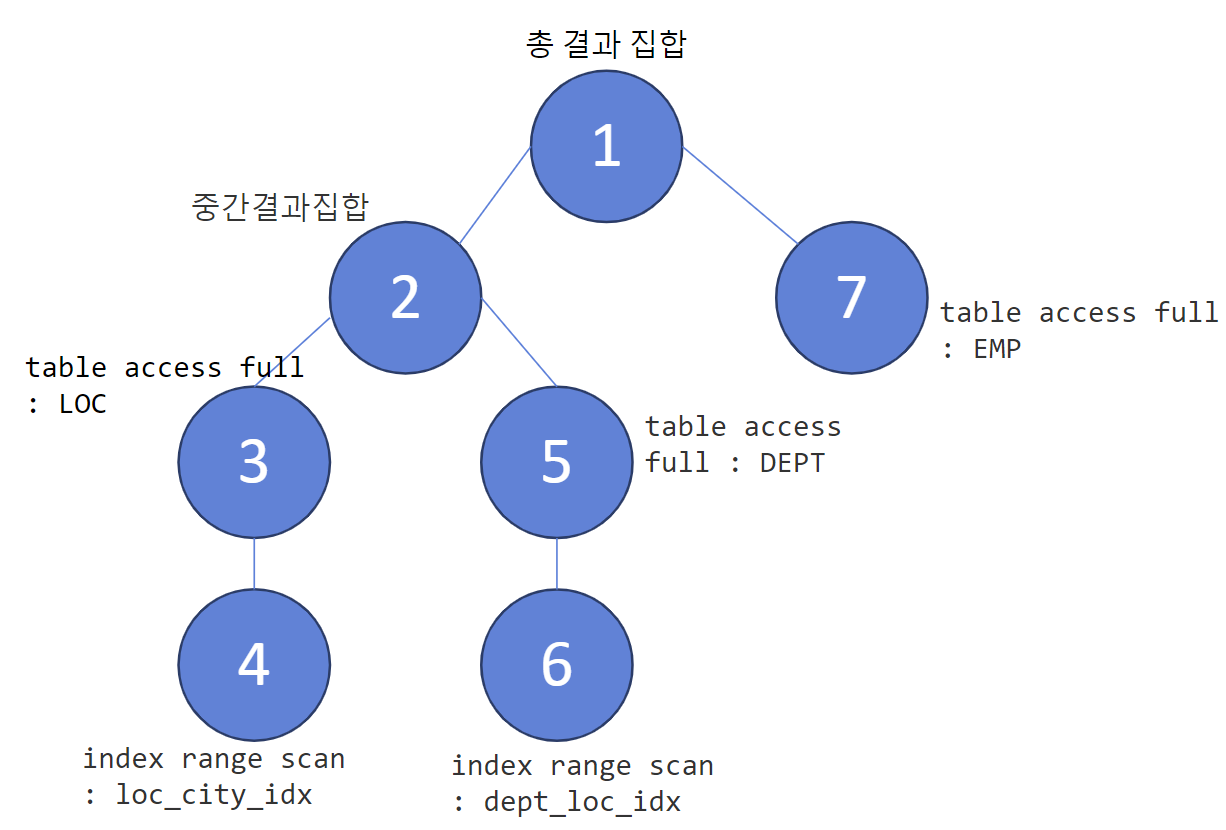
#) loc index 생성
#1) 인덱스(loc) 생성 후 확인
create index hr.loc_city_idx on hr.loc(city);
select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'LOC';
select /*+ gather_plan_statistics leading(l,d,e) use_nl(d) use_nl(e) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and l.city = 'Seattle';
#2) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
Id. 5번: : "D"."LOCATION_ID" index 생성 이 되어 있지 않아서 full scan 이 된다.

#) dept location_id 인덱스 생성
#1) 유니크 인덱스 생성 후 확인
create index hr.dept_loc_idx on hr.dept(location_id);
select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'DEPT';
#2) 힌트 사용
select /*+ gather_plan_statistics leading(l,d,e) use_nl(d) use_nl(e) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and l.city = 'Seattle';
#4) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
Id. 6번 먼저, buffer pinning 으로 i/o 줄어듦. → 5번 buffer pinning 이 돌아감.
Id. 7번: 부하가 가장 많음!
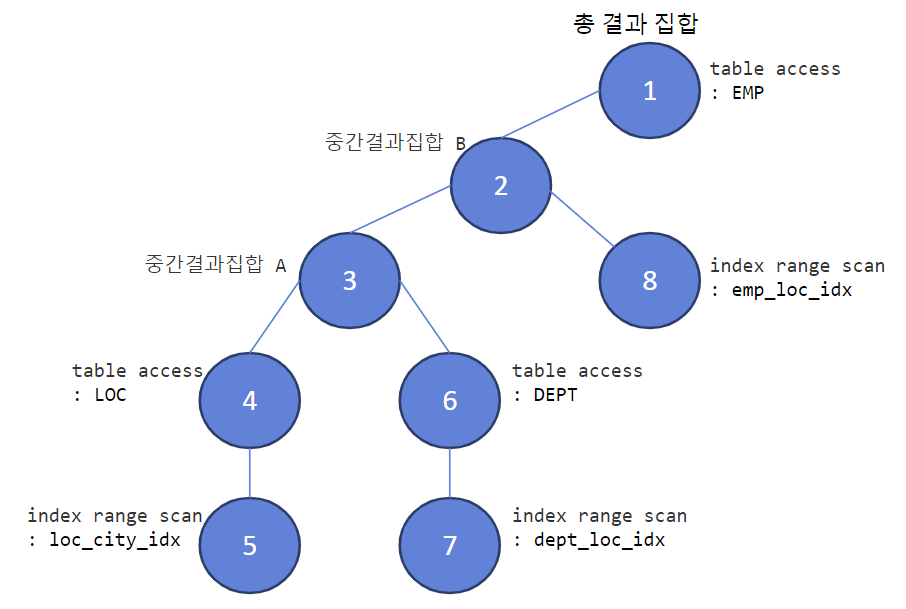
#) emp의 department_id 인덱스 설정
#1) 인덱스 생성 후 생성 확인
create index hr.emp_dept_idx on hr.emp(department_id);
select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'EMP';
#) 힌트 사용
select /*+ gather_plan_statistics leading(l,d,e) use_nl(d) use_nl(e) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and l.city = 'Seattle';
#) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
=> 8번을 봤을 경우, 배치i/o 기법은 보여지기만 하고 실제로는 수행되지는 않는다.

# 배치 i/o #
<sys sess>
alter system flush buffer_cache;
<hr sess>
select /*+ gather_plan_statistics leading(l,d,e) use_nl(d) no_nlj_batching(e) */ e.last_name, e.job_id, d.department_name, l.city
from emp e, dept d, loc l
where e.department_id = d.department_id
and d.location_id = l.location_id
and l.city = 'Seattle';
#3) 실행 계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
=> INDEX RANGE SCAN : inner 일 경우 여러번의 latch 을 잡아야 하니 buffer pinning 을 걸어 놓고 latch 및 i/o 의 성능을 줄이자
--> 메모리에 data가 없을경우 효과적이다. 같은 블록안에 data가 있을 경우(CLUSTERING FACTOR 좋은 경우)
=> ★ table prefetch(buffer pinning와 별개)
- 물리적 i/o 발생할 경우
- 디스트 i/o 를 수행하려면 비용이 많이 들기 때문에 한번에 i/o call 이 필요한 시점에 곧이어 읽을 가능성이 높은 block들을 data buffer cache에 미리 적재해 두는 기능
- inner 쪽에 non unique index를 range scan 시에 발생한다.
- index range scan은 single block i/o가 발생한다. 이때 발생하는 이벤트는 db file sequential read(피지컬 i/o)가 발생 할 수 있다. table prefetch 기능이 수행되면 db file paralle reads 이벤트가 발생한다.
(db file sequential read, db file paralle reads(중간에 발생한다.) 가 같이 발생할 수 도 있다.)
=> ★ batch i/o
- 물리적 i/o 발생할 경우
- table prefetch 보다 더 진화 과정
- inner 쪽 인덱스와 조인하면서 중간 결과 집합을 만든 후에 inner 쪽 테이블과 일괄 (batch) 처리한다.
'Data Base > SQL 튜닝' 카테고리의 다른 글
| Sort Merge Join (0) | 2024.02.20 |
|---|---|
| join 실행 계획 (0) | 2024.02.19 |
| sort operation, 정렬 작업, 실행 계획, join 순서 (0) | 2024.02.17 |
| batch i/o, table prefetch, 옵티마이저 (0) | 2024.02.17 |
| PGA, 자동 PGA 메모리 관리 (1) | 2024.02.17 |