■ Sort Merge Join(정렬 병합 조인)
1. 개념 및 설명
- 조인되는 건수가 많을때 효율적인 조인방법이다.
- 대용량 데이터셋 간의 조인에서 사용되며, 정렬 작업에 대한 성능 문제가 발생할 수 있다.
2. 성능 및 힌트
- 조인 대상인 테이블이 크고 조인되는 건수가 많을때 유리하다.
- sort에 대한 성능 문제가 있을 수 있으므로, 주의가 필요없다.
- 사용가능한 힌트: 'use_merge()', 'leading()'
1) use_merge(): sort merge join 사용 힌트
2) leading(): 조인 집합 중 어느 쪽을 먼저 수행할지에 대한 힌트, 일반적으로 한 쪽 집합을 먼저 수행하는 것이 성능상 이점이 있다.
3. 주의사항
- 조인할 테이블이 대용량이거나 조인 건수가 많을 때 사용하는 것이 효과적이다.
- 정렬 작업에 대한 성능 이슈를 고려해야 하며, 적절한 인덱스를 활용하여 성능을 최적화해야 한다.
tip) 1쪽 집합을 first로 가는 것이 일반적이다.
#) 힌트 사용 없이 수행
select /*+ gather_plan_statistics */ e.employee_id, e.job_id, d.department_name
from employees e, departments d
where e.department_id = d.department_id;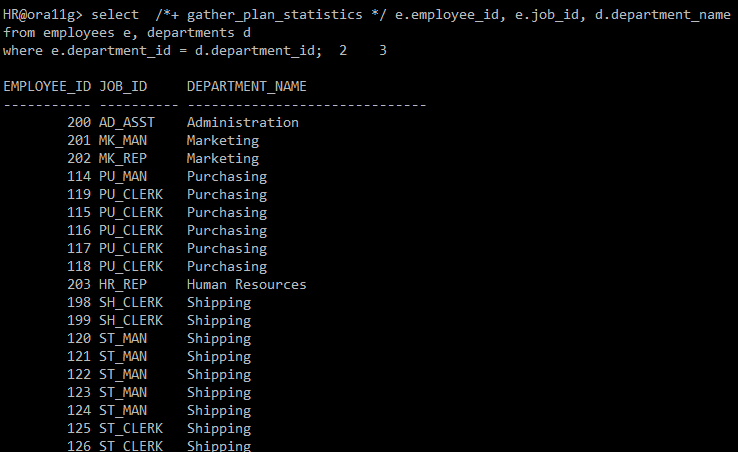
#2) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
#) deparment_id 기준으로 오름차순
<hr sess_emp> : n쪽 집합, second, 중복성있는 data
select department_id, employee_id, job_id
from employees
order by department_id;
<hr sess_dept> : 1쪽 집합, first, 중복성없는 data
select department_id, department_name
from departments
order by department_id;
#) 힌트 사용: leading(), use_merge()
select /*+ gather_plan_statistics leading(e,d) use_merge(d) */ e.employee_id, e.job_id, d.department_name
from employees e, departments d
where e.department_id = d.department_id;
#2) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
Id. 4 : 메모리 사용량 증가 / index key 컬럼이 있으나, 타지 않음.

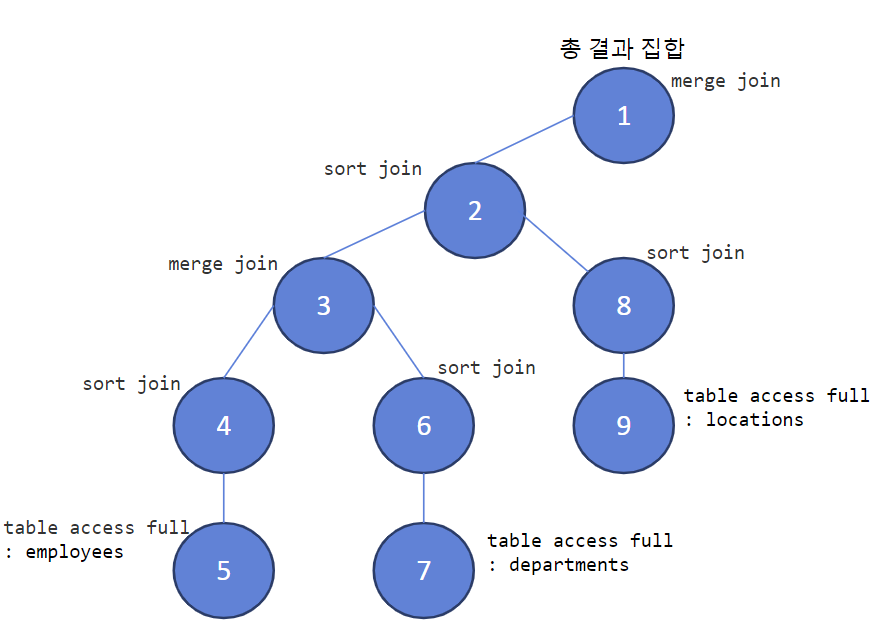
#1) locations 테이블 추가 + leading(e,d,l) use_merge(d) use_merge(l)
select /*+ gather_plan_statistics leading(e,d,l) use_merge(d) use_merge(l)*/ e.employee_id, e.job_id, d.department_name, l.city, l.street_address
from employees e, departments d, locations l
where e.department_id = d.department_id
and d.location_id = l.location_id;
#2) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
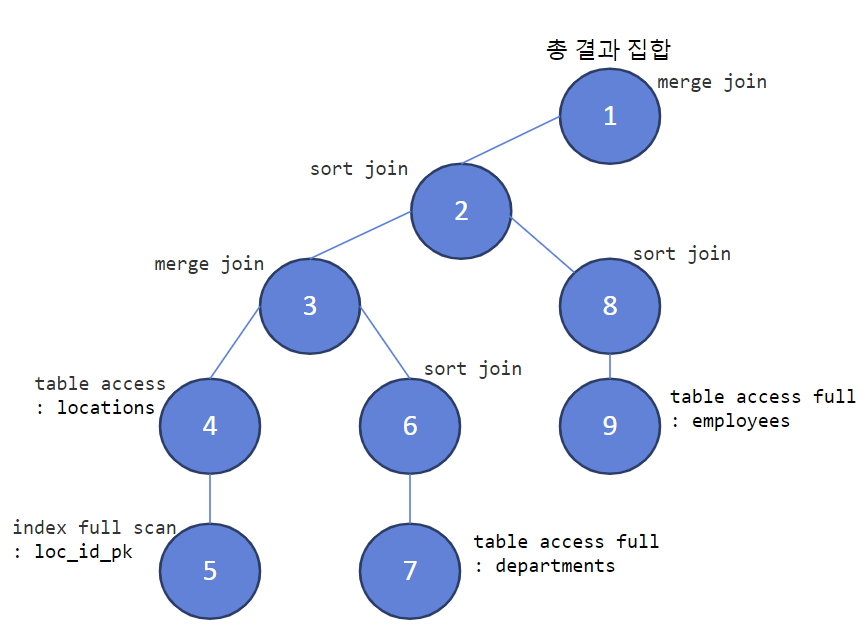
#1) locations 테이블 추가 + leading(l,d,e) use_merge(d) use_merge(e)
select /*+ gather_plan_statistics leading(l,d,e) use_merge(d) use_merge(e)*/ e.employee_id, e.job_id, d.department_name, l.city, l.street_address
from employees e, departments d, locations l
where e.department_id = d.department_id
and d.location_id = l.location_id;
#2) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
#1) locations 테이블 추가 + leading(l,d,e) use_merge(d) use_merge(e)
select /*+ gather_plan_statistics leading(l,d,e) use_nl(d) use_nl(e)*/ e.employee_id, e.job_id, d.department_name, l.city, l.street_address
from employees e, departments d, locations l
where e.department_id = d.department_id
and d.location_id = l.location_id;
#2) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));

# 대용량 table #
#1) 기존 table 삭제
drop table hr.emp purge;
#2) 대용량 table 생성
create table hr.emp
nologging
as select rownum emp_id, last_name, first_name, hire_date, job_id, salary, department_id
from hr.employees, (select rownum emp_id from dual connect by level <= 1000);
#3) 힌트사용: leading(e,d) use_merge(d)
select /*+ gather_plan_statistics leading(e,d) use_merge(d) */ e.emp_id, e.job_id, d.department_name
from emp e, dept d
where e.department_id = d.department_id;
#4) 실행계획 확인
-- A-Time 을 봤을때 오래걸려, 악성코드이다.
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));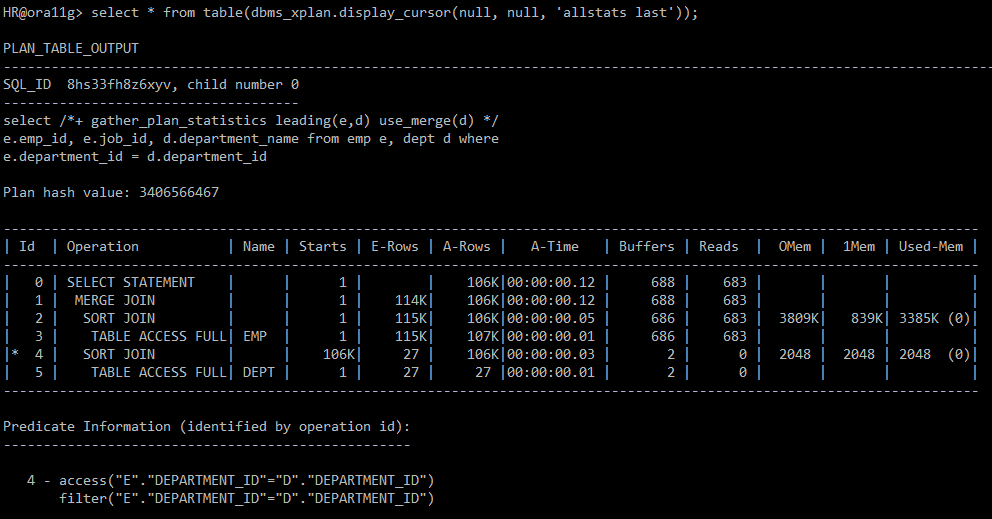
#) 힌트 사용: leading(d,e) use_merge(e)
select /*+ gather_plan_statistics leading(d,e) use_merge(e) */ e.emp_id, e.job_id, d.department_name
from emp e, dept d
where e.department_id = d.department_id;
#) 실행계획 확인
select * from table(dbms_xplan.display_cursor(null, null, 'allstats last'));
'Data Base > SQL 튜닝' 카테고리의 다른 글
| pushing subquery, view merging, join 조건 pushdown (0) | 2024.02.23 |
|---|---|
| hash join (0) | 2024.02.23 |
| join 실행 계획 (0) | 2024.02.19 |
| join 문, index 설정 (0) | 2024.02.19 |
| sort operation, 정렬 작업, 실행 계획, join 순서 (0) | 2024.02.17 |