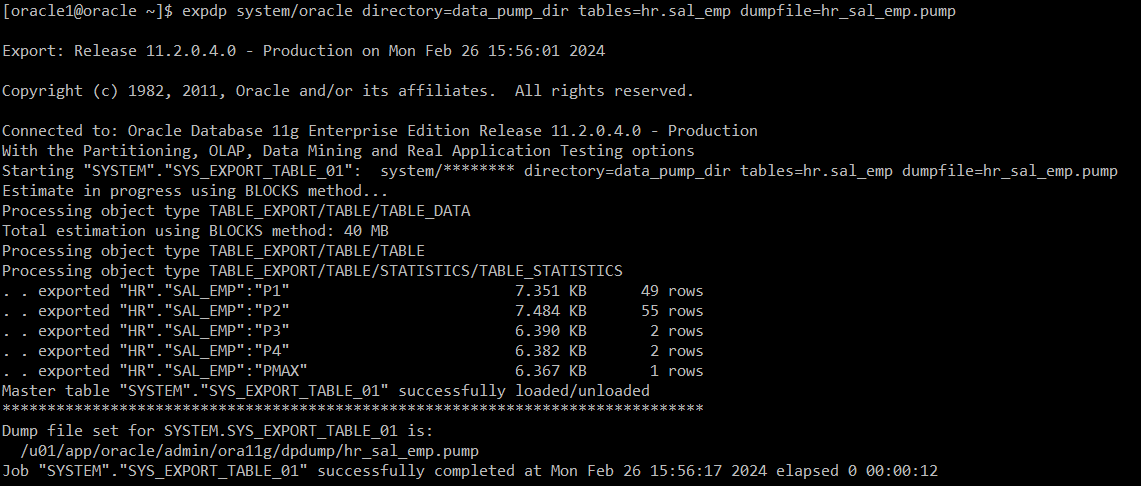
#) 대용량 table drop table hr.sal_emp purge; => Table dropped. create table hr.sal_emp nologging as select rownum as employee_id, last_name, first_name, hire_date, job_id, salary, manager_id, department_id from employees e, (select level as id from dual connect by level Table created. select * from hr.sal_emp where salary between 5000 and 8000; => 125000 rows selected. #) 통계 수집 exec dbms_stats.gath..