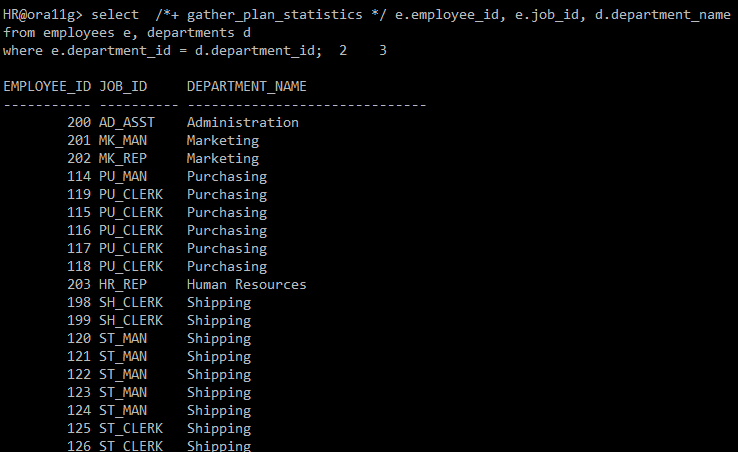
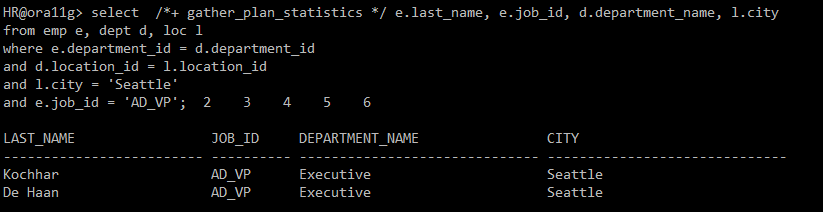
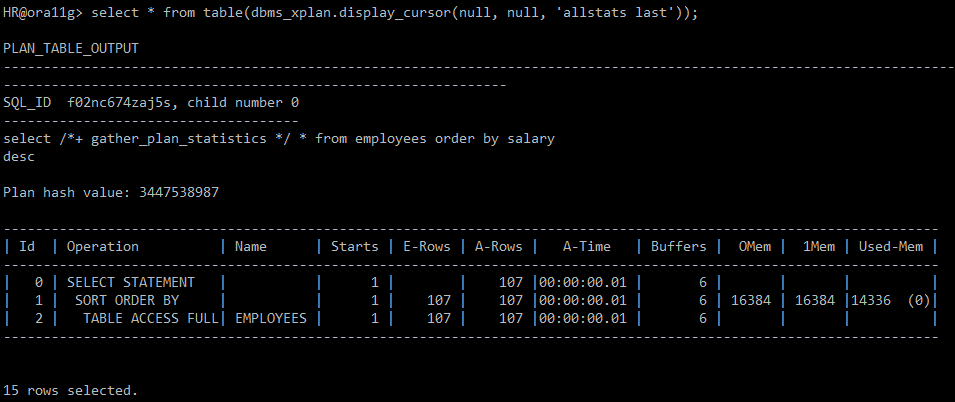
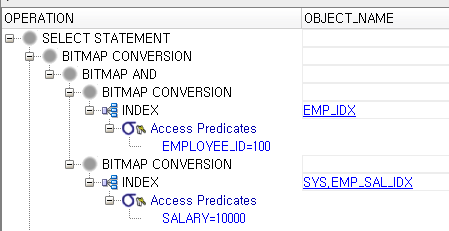
■ pushing subquery 1. 정의 - 실행 계획의 초기 단계에서 서브쿼리 필터링을 먼저 처리하여, 다음 수행 단계로 전달되는 행의 수를 줄일 수 있는 기능 - Unnesting되지 않은 서브쿼리의 처리 순서를 제어하여 최적화된 실행 계획을 구성하는 방법 중 하나이다. 2. 힌트 - `push_subq` 힌트는 Oracle Optimizer에게 서브쿼리를 최적화하는 방식을 알려주는 역할이다. - 이 힌트를 사용하면 서브쿼리의 필터링을 가능한 한 빨리 수행하도록 유도하여 효율적인 실행 계획을 생성할 수 있다. 3. 활용 - 서브쿼리가 Unnesting되지 않았을 때, 전체 테이블을 스캔하는 비효율적인 실행 계획을 방지하고자 할 때 Pushing Subquery를 사용한다. - Pushing Sub..